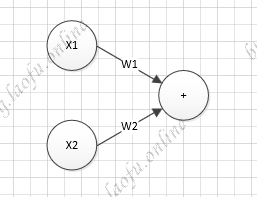
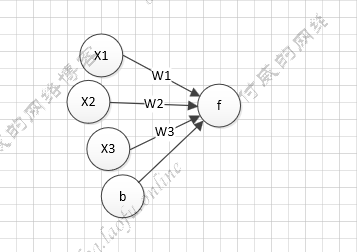
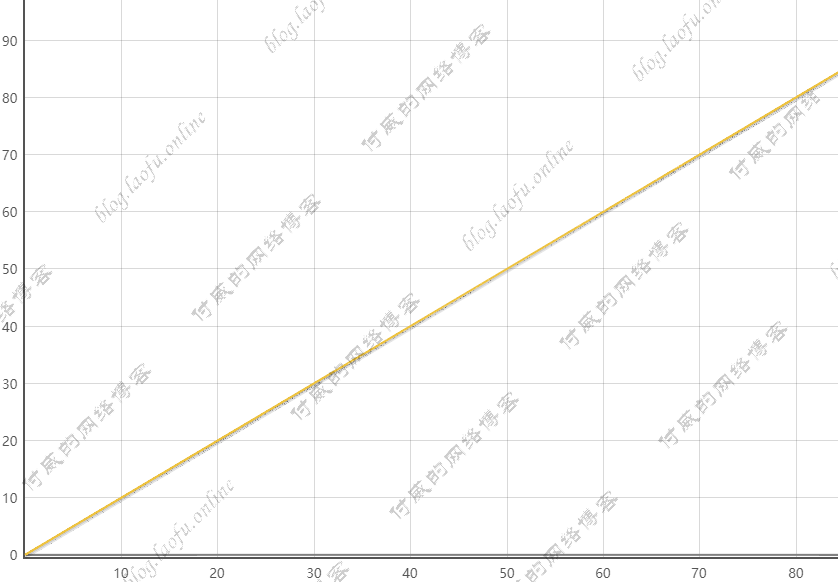
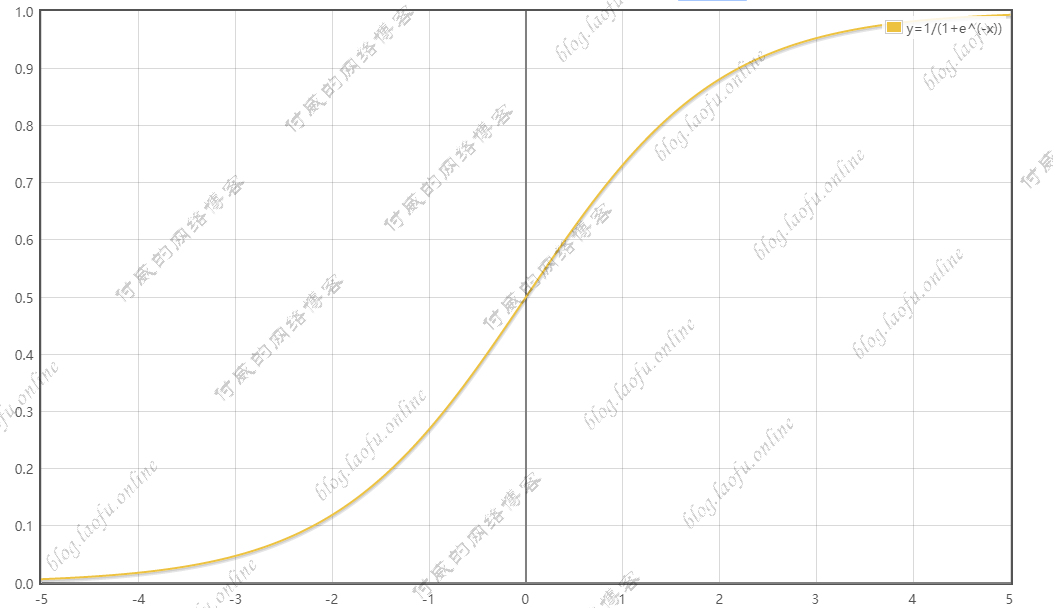
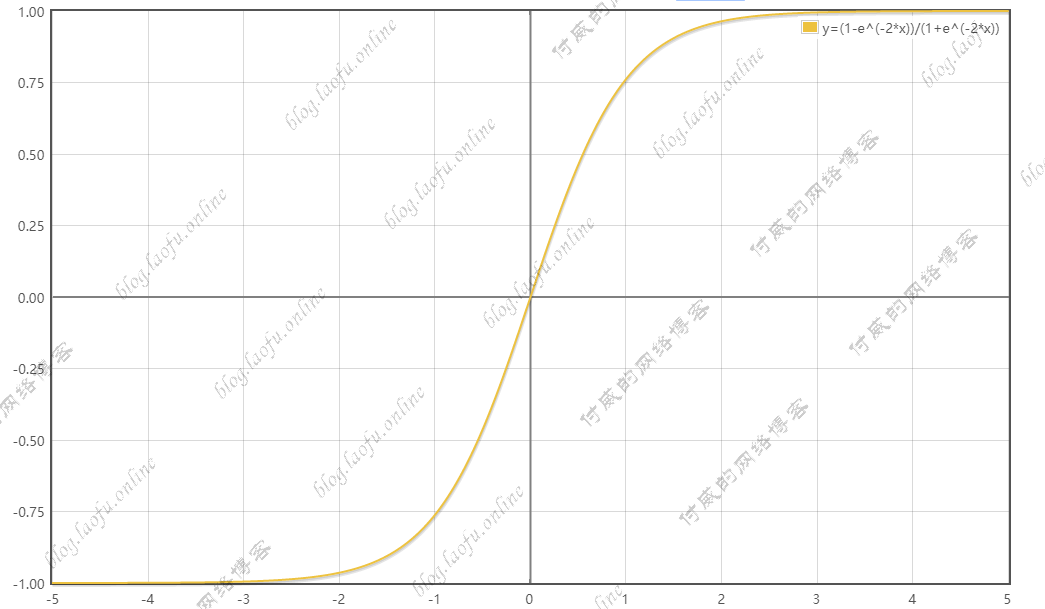
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| After 0 ,global_step is 1,w is 3.800000,learning_rate is 0.099000,loss is 23.040001
After 1 ,global_step is 2,w is 2.849600,learning_rate is 0.098010,loss is 14.819419
After 2 ,global_step is 3,w is 2.095001,learning_rate is 0.097030,loss is 9.579033
After 3 ,global_step is 4,w is 1.494386,learning_rate is 0.096060,loss is 6.221961
After 4 ,global_step is 5,w is 1.015167,learning_rate is 0.095099,loss is 4.060896
After 5 ,global_step is 6,w is 0.631886,learning_rate is 0.094148,loss is 2.663051
After 6 ,global_step is 7,w is 0.324608,learning_rate is 0.093207,loss is 1.754587
After 7 ,global_step is 8,w is 0.077684,learning_rate is 0.092274,loss is 1.161403
After 8 ,global_step is 9,w is -0.121202,learning_rate is 0.091352,loss is 0.772287
After 9 ,global_step is 10,w is -0.281761,learning_rate is 0.090438,loss is 0.515867
After 10 ,global_step is 11,w is -0.411674,learning_rate is 0.089534,loss is 0.346128
After 11 ,global_step is 12,w is -0.517024,learning_rate is 0.088638,loss is 0.233266
After 12 ,global_step is 13,w is -0.602644,learning_rate is 0.087752,loss is 0.157891
After 13 ,global_step is 14,w is -0.672382,learning_rate is 0.086875,loss is 0.107334
After 14 ,global_step is 15,w is -0.729305,learning_rate is 0.086006,loss is 0.073276
After 15 ,global_step is 16,w is -0.775868,learning_rate is 0.085146,loss is 0.050235
After 16 ,global_step is 17,w is -0.814036,learning_rate is 0.084294,loss is 0.034583
After 17 ,global_step is 18,w is -0.845387,learning_rate is 0.083451,loss is 0.023905
After 18 ,global_step is 19,w is -0.871193,learning_rate is 0.082617,loss is 0.016591
After 19 ,global_step is 20,w is -0.892476,learning_rate is 0.081791,loss is 0.011561
After 20 ,global_step is 21,w is -0.910065,learning_rate is 0.080973,loss is 0.008088
After 21 ,global_step is 22,w is -0.924629,learning_rate is 0.080163,loss is 0.005681
After 22 ,global_step is 23,w is -0.936713,learning_rate is 0.079361,loss is 0.004005
After 23 ,global_step is 24,w is -0.946758,learning_rate is 0.078568,loss is 0.002835
After 24 ,global_step is 25,w is -0.955125,learning_rate is 0.077782,loss is 0.002014
After 25 ,global_step is 26,w is -0.962106,learning_rate is 0.077004,loss is 0.001436
After 26 ,global_step is 27,w is -0.967942,learning_rate is 0.076234,loss is 0.001028
After 27 ,global_step is 28,w is -0.972830,learning_rate is 0.075472,loss is 0.000738
After 28 ,global_step is 29,w is -0.976931,learning_rate is 0.074717,loss is 0.000532
After 29 ,global_step is 30,w is -0.980378,learning_rate is 0.073970,loss is 0.000385
After 30 ,global_step is 31,w is -0.983281,learning_rate is 0.073230,loss is 0.000280
After 31 ,global_step is 32,w is -0.985730,learning_rate is 0.072498,loss is 0.000204
After 32 ,global_step is 33,w is -0.987799,learning_rate is 0.071773,loss is 0.000149
After 33 ,global_step is 34,w is -0.989550,learning_rate is 0.071055,loss is 0.000109
After 34 ,global_step is 35,w is -0.991035,learning_rate is 0.070345,loss is 0.000080
After 35 ,global_step is 36,w is -0.992297,learning_rate is 0.069641,loss is 0.000059
After 36 ,global_step is 37,w is -0.993369,learning_rate is 0.068945,loss is 0.000044
After 37 ,global_step is 38,w is -0.994284,learning_rate is 0.068255,loss is 0.000033
After 38 ,global_step is 39,w is -0.995064,learning_rate is 0.067573,loss is 0.000024
After 39 ,global_step is 40,w is -0.995731,learning_rate is 0.066897,loss is 0.000018
|
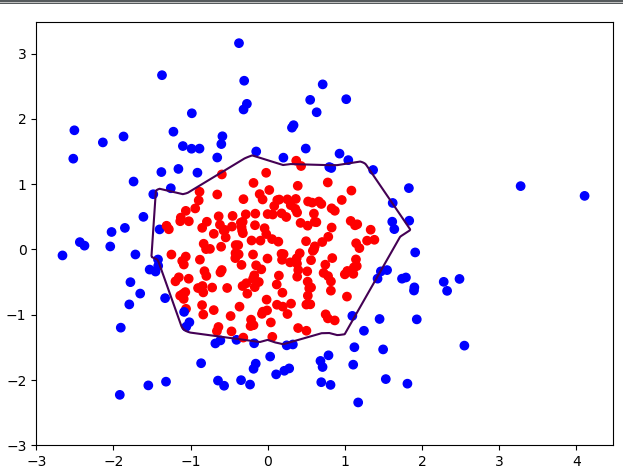
 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}  {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}  {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}  {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}  {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 



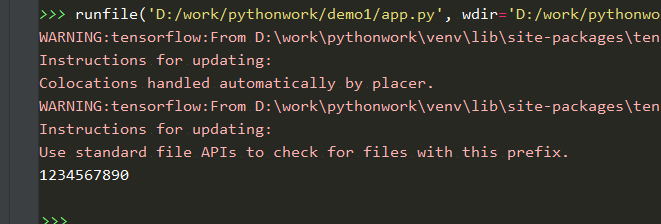
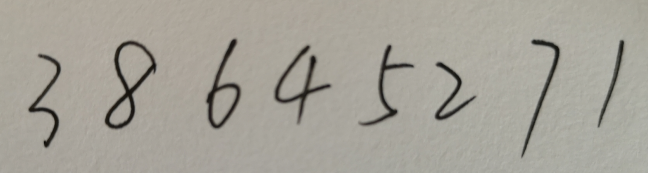
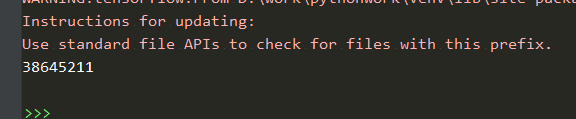
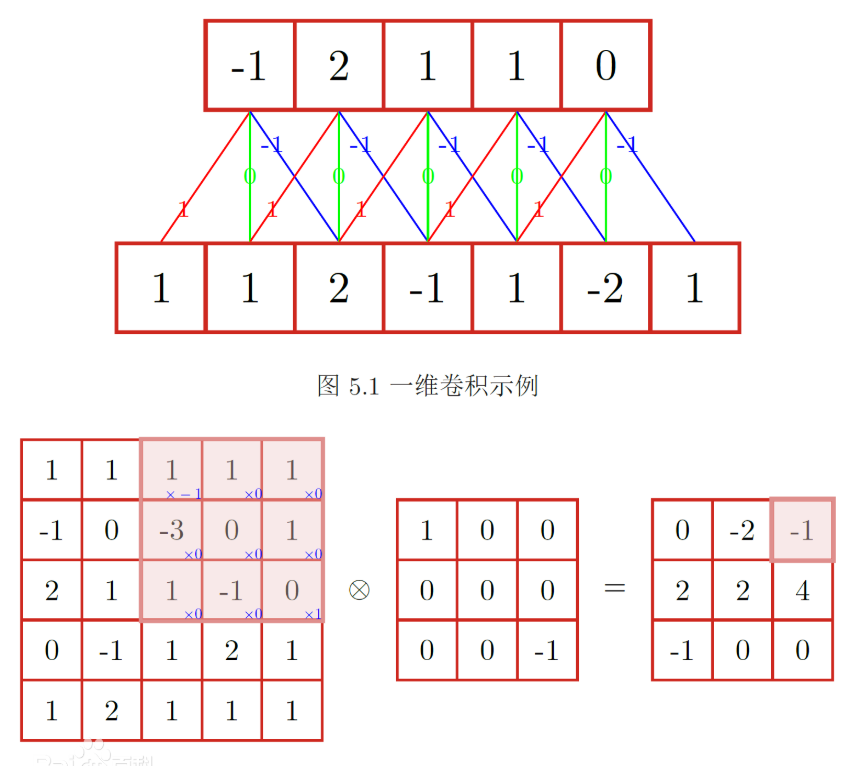 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 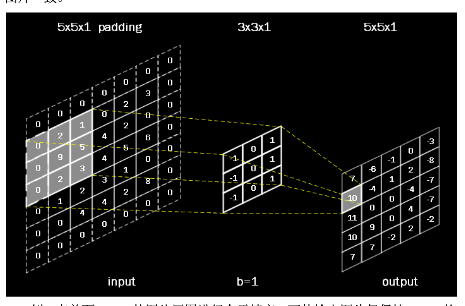 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 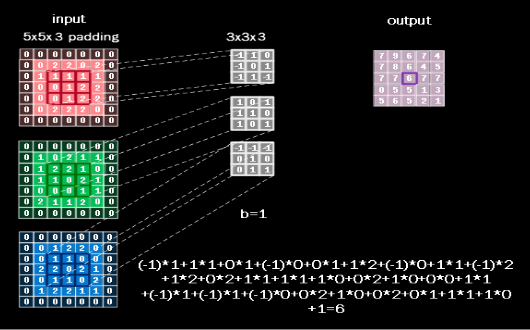 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}  {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 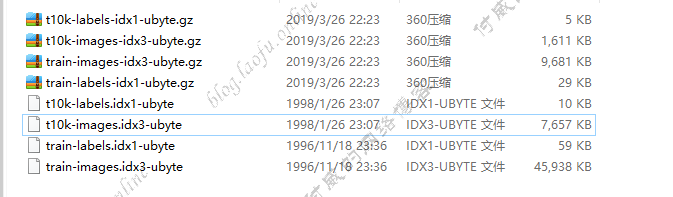 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 
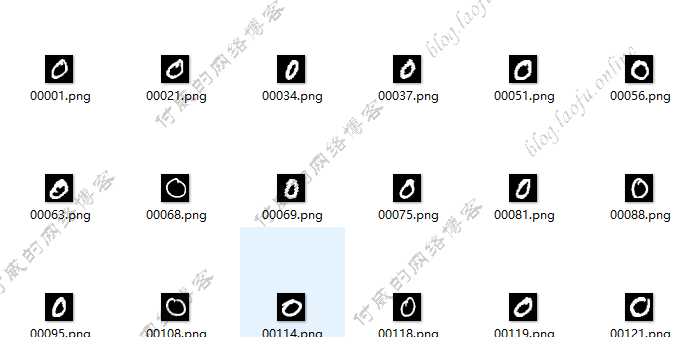
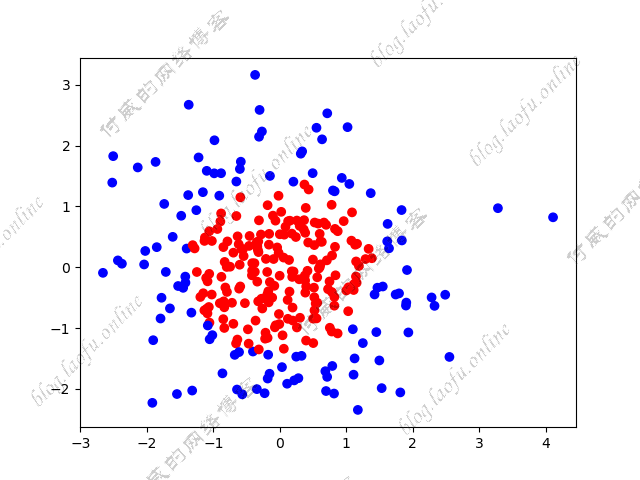 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 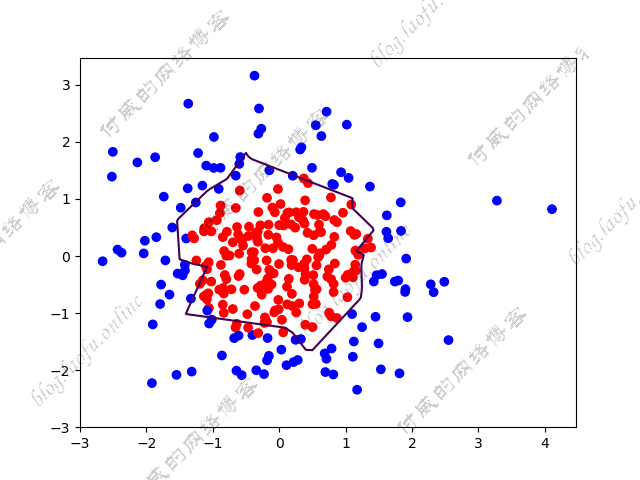 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 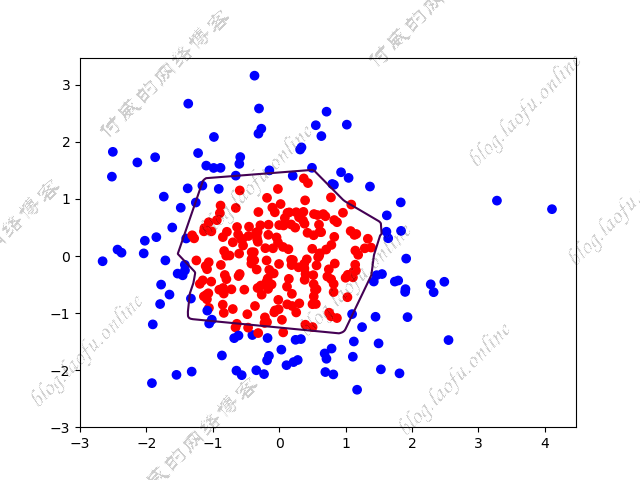 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 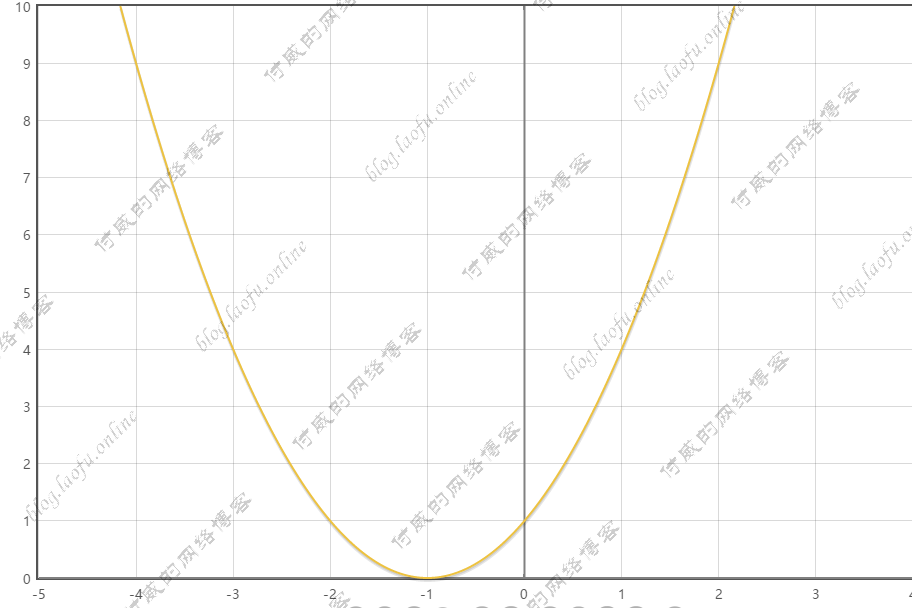 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}