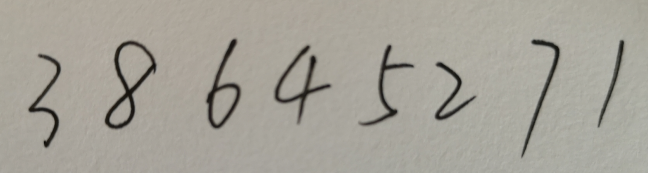defcorp_img(image): h, w = image.shape[:2] xArr = [] yArr = [] imgArr = [] resultImgArr = [] for x inrange(w): xSum = np.transpose(image)[x].sum() if xSum / h != 255: xArr.append(x) else: iflen(xArr) > 0: cropped = image[0:h, min(xArr):max(xArr)] imgArr.append(cropped) xArr.clear()
for img in imgArr: for y inrange(h): yw = img.shape[-1] ySum = img[y].sum() if (ySum / yw) != 255: yArr.append(y) else: if (len(yArr) > 0): cropped = img[min(yArr):max(yArr), 0:yw] resultImgArr.append(cropped) yArr.clear() return resultImgArr;
import tensorflow as tf INPUT_NODE=784 OUTPUT_NODE=10 LAYER1_NODE=500 #定义输入输出参数和前向传播过程 defget_weight(shape,regularizer): w=tf.Variable(tf.random_normal(shape),dtype=tf.float32) if regularizer!=None: tf.add_to_collection("losses",tf.contrib.layers.l2_regularizer(regularizer)(w)) return w
defget_bias(shape): b=tf.Variable(tf.constant(0.01,shape=shape)) return b
# 对所有的参数都使用滑动平均,更准确的定义模型。 ema=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step) emp_op=ema.apply(tf.trainable_variables()) with tf.control_dependencies([train_step,emp_op]): train_op=tf.no_op(name="train")
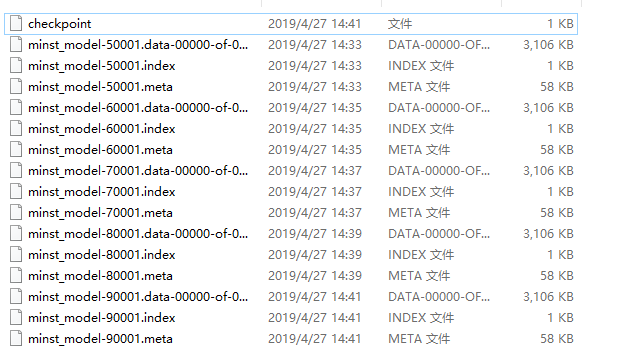
saver=tf.train.Saver()
with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op)
ckpt=tf.train.get_checkpoint_state(MODEL_SAVE_PATH) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess,ckpt.model_checkpoint_path)
for i inrange(STEPS): xs,ys =minst.train.next_batch(BATCH_SIZE) _,loss_value,step=sess.run([train_op,loss,global_step],feed_dict={x:xs,y_:ys})#喂入神经网络数据
if i%1000==0: print("After %d training step(s),loss on training batch is %g."%(step,loss_value)) saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
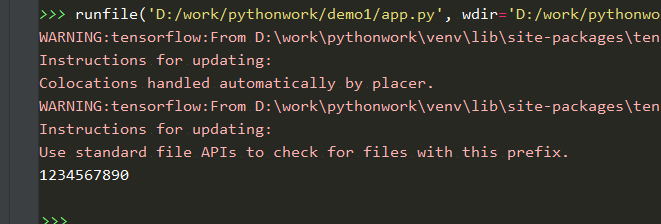
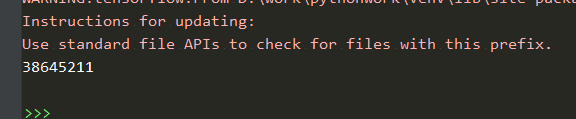
import imageUtils import tensorflow as tf import minst_forward import minst_backward import numpy as np import cv2 as cv
defrestore_model(imgArr): with tf.Graph().as_default() as tg: x = tf.placeholder(tf.float32, [None, minst_forward.INPUT_NODE]) y = minst_forward.forward(x, None) preValue = tf.argmax(y, 1) # 得到概率最大的预测值
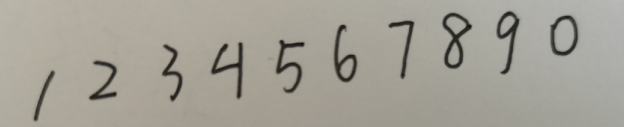 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 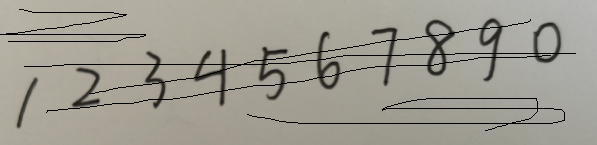 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 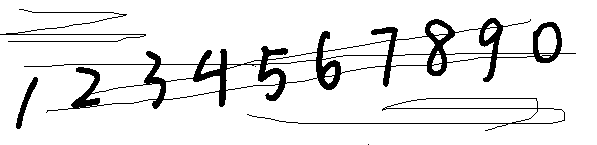 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”} 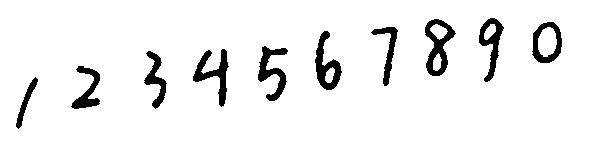 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}  {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}