三层架构的问题
在前文中,我从基础代码的角度探讨了如何运用领域驱动设计(DDD)来实现高内聚低耦合的代码。本篇文章将从项目架构的角度,继续探讨三层架构与DDD之间的演化过程,以及DDD如何优化架构的问题。
在前文中,我从基础代码的角度探讨了如何运用领域驱动设计(DDD)来实现高内聚低耦合的代码。本篇文章将从项目架构的角度,继续探讨三层架构与DDD之间的演化过程,以及DDD如何优化架构的问题。
在2019年我初次接触到领域驱动设计(Domain-Driven Design,简称DDD)的概念。在我的探索中,我发现许多有关DDD的教程过于偏重于战略设计,充斥着许多晦涩难懂的概念,导致阅读起来相当艰难。有些教程往往只是解释了DDD的概念,而未深入探讨为何要采用这种方式以及这样做能带来哪些好处,这导致很多人在实践应用DDD时遇到了诸多难题。甚至有些人为了引入DDD而在项目中强制采用DDD架构,结果却意外增加了代码的复杂性,带来了一系列潜在的风险。
1 | Semaphore semaphore = new Semaphore(nThread);//定义几个许可 |
线程池的在 Java并发中使用最多的一种手段,也是性能和易用性相对来说比较均衡的方式,下面我们就一起探索先线程池的原理。
对于线程池的使用,在这篇文章中就不过多的赘述,首先我们先看下线程池的分配线程的逻辑。
我们知道,在创建线程池的有 7 个核心的参数:
在学习 DDD 架构前,一直觉得三层架构结构在业务复杂的场景会带来很多很多的问题,但是一直都处于模糊不清的形态,无法准确的定义。直到学习了DDD 的概念。
为了更好的学习 DDD ,我们总结一下三层架构在业务复杂的场景带来的问题,首先看下正常的项目依赖图
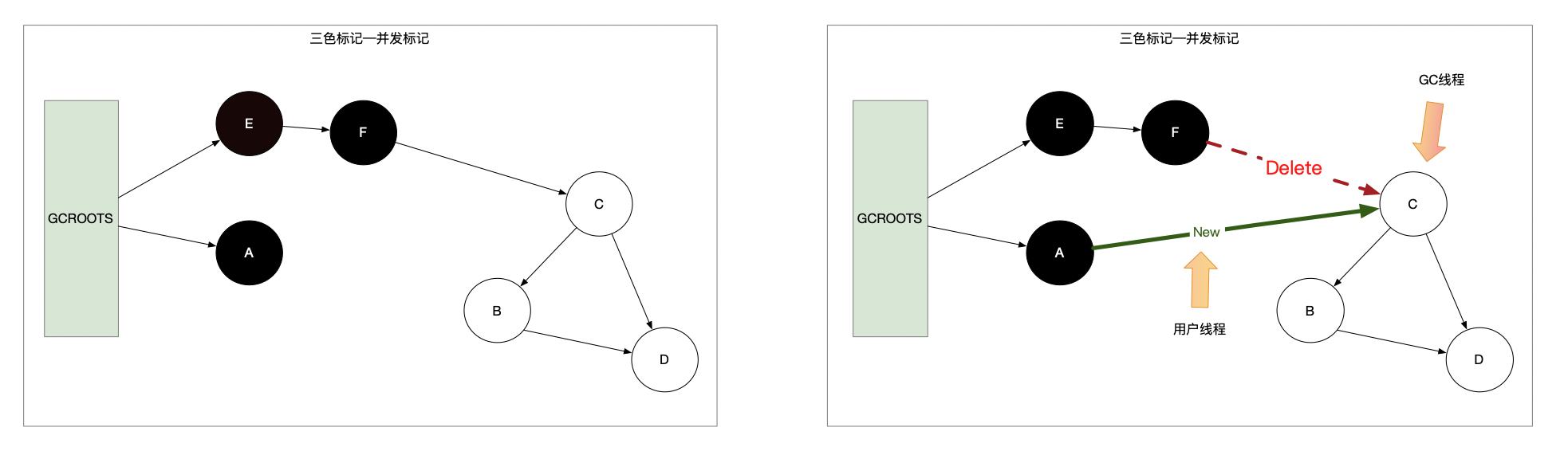
为了提供 JVM 垃圾回收的性能,从 CMS 垃圾收集器开始,引入了并发标记的概念(此处的并发标记是指与用户线程一起工作)。引入并发标记的过程就会带来一个问题,在业务执行的过程中,会对现有的引用关系链出现改变。具体如下图:
1 | import com.google.common.base.Stopwatch; |
1 |
|
这篇博客是为了深入探究 Java 中对象的知识。
首先我们先看下一个简单创建对象的代码,看一个对象到底是如何在内存中创建的。
1 | public static void main(String[] args) { |
为了更清楚的看 synchronized 的锁的升级的过程,我们用代码来打印对象的布局,使用的类库是:
1 | <dependency> |
Update your browser to view this website correctly.&npsb;Update my browser now
