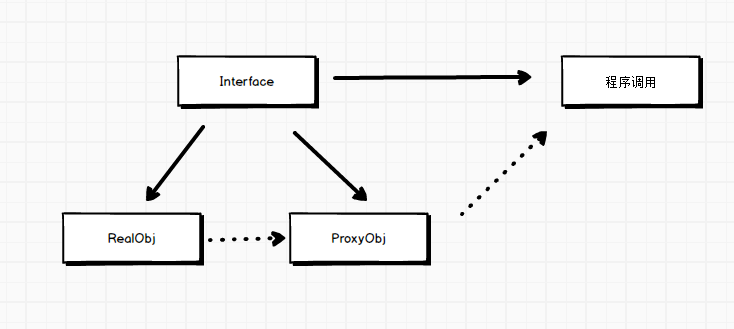
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| public class Student {
public Student(String stuName, int age, BigDecimal score, int clazz) {
this.stuName = stuName;
this.age = age;
this.score = score;
this.clazz = clazz;
}
private String stuName;
private int age;
private BigDecimal score;
private int clazz;
public String getStuName() {
return stuName;
}
public void setStuName(String stuName) {
this.stuName = stuName;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public BigDecimal getScore() {
return score;
}
public void setScore(BigDecimal score) {
this.score = score;
}
public int getClazz() {
return clazz;
}
public void setClazz(int clazz) {
this.clazz = clazz;
}
}
List<Student> studentList = new ArrayList<>();
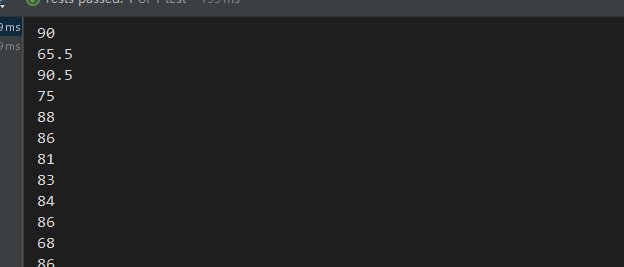
studentList.add(new Student("黎 明", 20, new BigDecimal(80), 1));
studentList.add(new Student("郭敬明", 22, new BigDecimal(90), 2));
studentList.add(new Student("明 道", 21, new BigDecimal(65.5), 3));
studentList.add(new Student("郭富城", 30, new BigDecimal(90.5), 4));
studentList.add(new Student("刘诗诗", 20, new BigDecimal(75), 1));
studentList.add(new Student("成 龙", 60, new BigDecimal(88), 5));
studentList.add(new Student("郑伊健", 60, new BigDecimal(86), 1));
studentList.add(new Student("刘德华", 40, new BigDecimal(81), 1));
studentList.add(new Student("古天乐", 50, new BigDecimal(83), 2));
studentList.add(new Student("赵文卓", 40, new BigDecimal(84), 2));
studentList.add(new Student("吴奇隆", 30, new BigDecimal(86), 4));
studentList.add(new Student("言承旭", 50, new BigDecimal(68), 1));
studentList.add(new Student("郑伊健", 60, new BigDecimal(86), 1));
studentList.add(new Student("黎 明", 20, new BigDecimal(80), 1));
studentList.add(new Student("李连杰", 65, new BigDecimal(86), 4));
studentList.add(new Student("周润发", 69, new BigDecimal(58), 1));
studentList.add(new Student("徐若萱", 28, new BigDecimal(88), 6));
studentList.add(new Student("许慧欣", 26, new BigDecimal(86), 8));
studentList.add(new Student("陈慧琳", 35, new BigDecimal(64), 1));
studentList.add(new Student("关之琳", 45, new BigDecimal(50), 9));
studentList.add(new Student("温碧霞", 67, new BigDecimal(53), 2));
studentList.add(new Student("林青霞", 22, new BigDecimal(56), 3));
studentList.add(new Student("李嘉欣", 25, new BigDecimal(84), 1));
studentList.add(new Student("彭佳慧", 26, new BigDecimal(82), 5));
studentList.add(new Student("陈紫涵", 39, new BigDecimal(88), 1));
studentList.add(new Student("张韶涵", 41, new BigDecimal(90), 6));
studentList.add(new Student("梁朝伟", 58, new BigDecimal(74), 1));
studentList.add(new Student("梁咏琪", 65, new BigDecimal(82), 7));
studentList.add(new Student("范玮琪", 22, new BigDecimal(83), 1));
|
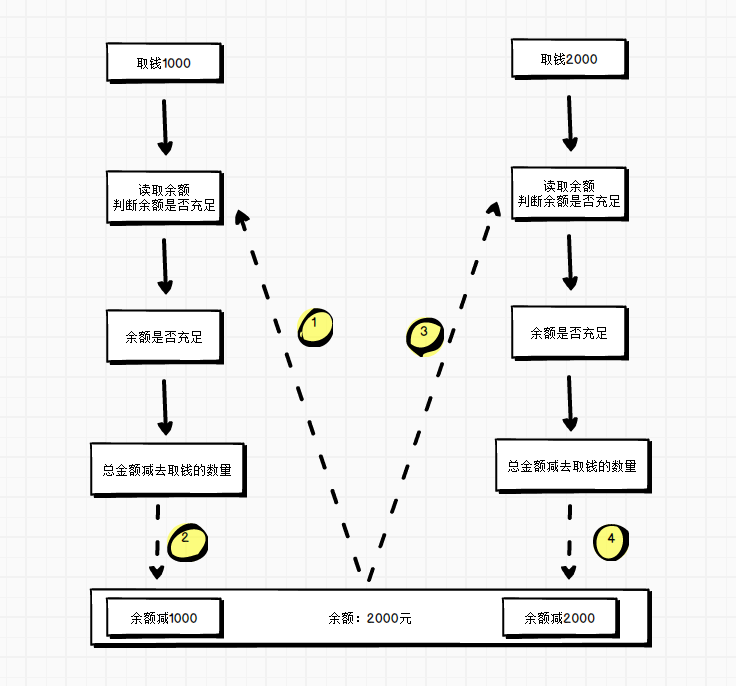
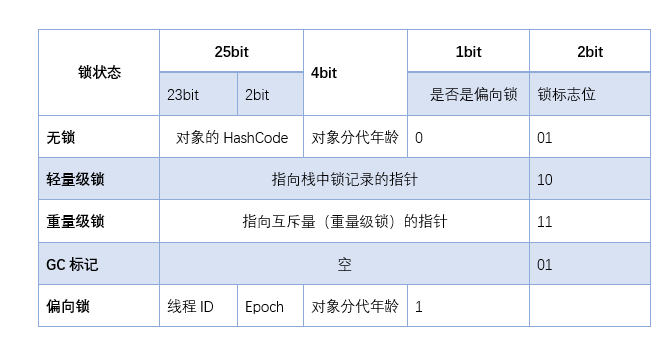
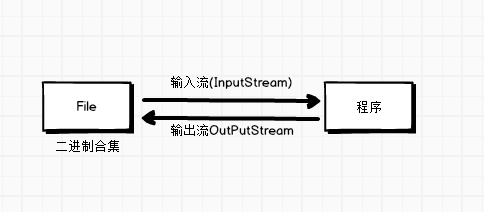




 ]
]