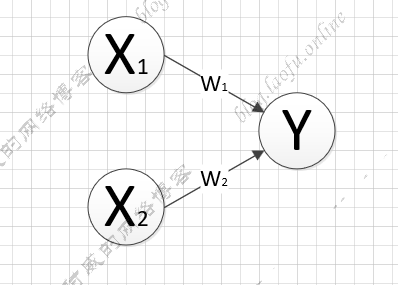
输入参数 在上面一篇博客提到的一个简单的模型:
为了能够得到Y,需要准确的知道$$w_1,w_2$$的值,一般都是先随机给一个值,后面利用样本进行训练,得到准确的值。例如使用随机方法赋初值:
w=tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1))
其中:random_normal代表随机正态分布,[2,3]产生2x3的矩阵,stddev=2代表标准差是2,mean=0均值为0,seed=1随机种子。(标准差,均值,随机种子可以不写)
除了random_normal方法外还有几个其他的生成函数:
truncated_normal:去掉过大偏离点的正态分布,如果生成的数据超过了平均值两个标准差,数据将重新生成。
random_uniform:平均分布
tf.zeros:生成全0数组,tf.zeros([3,2],int32) 生成[[0,0],[0,0],[0,0]]tf.ones:生成全1数组,tf.zeros([3,2],int32) 生成[[1,1],[1,1],[1,1]]tf.fill:全定值数组,tf.zeros([3,2],6) 生成[[6,6],[6,6],[6,6]]tf.constant:直接给值,tf.constant([3,2,1]) 生成[3,2,1]
神经网络的实现过程
准备数据集,提取特征,作为输入喂给神经网络
搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
大量特征数据喂给NN,迭代优化NN参数
使用训练好的模型预测和分类
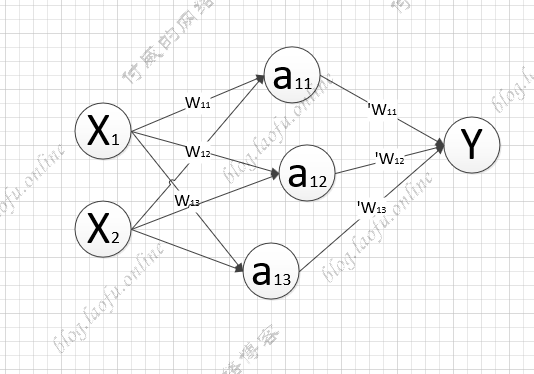
前向传播 比如生产一批零件,将体积$$x_1$$和重量$$x_2$$为特征输入到NN,通过NN后输出一个值。 具体的预测结果如下:
具体的Y值的计算是:$$Y=a_{11}w_{11}+ a_{12}w_{21}+a_{13}w_{31}$$;
我们把上面的过程用tensorflow表示出来,先定义几个变量:
输入参数X的权重矩阵:
隐藏层的矩阵:
隐藏层到输入结果的矩阵:
由此可以得到:
a=tf.matmaul(X,W)
Y=tf.matmaul(a,'W)
分析过程
变量初始化,计算图节点,运算都需要sesion
变量初始化:在session.run函数中,使用tf.global_variables_initializer()
1 2 init_op=tf.global_variables_initializer() sess.run(init_op)
计算图节点运算:在sess.run函数中写入待运算的节点sess.run(y)
使用tf.placeholder占位,在sess.run函数中用feed_dict喂数据
喂一组数据:
1 2 x=tf.placeholder(tf.float32,shape=(1 ,2 )) sess.run(y,feed_dict={x:[[0.5 ,0.6 ]]})
喂多组数据:
1 2 x=tf.placeholder(tf.float32,shape=(None ,2 )) sess.run(y,feed_dict={x:[[0.5 ,0.6 ],[0.5 ,0.6 ]]})
使用代码实现上面的分析过程(喂入多组数据):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import tensorflow as tfx=tf.placeholder(tf.float32,shape=(None ,2 )) w1=tf.Variable(tf.random_normal([2 ,3 ],stddev=1 ,seed=1 )) w2=tf.Variable(tf.random_normal([3 ,1 ],stddev=1 ,seed=1 )) a=tf.matmul(x,w1) y=tf.matmul(a,w2) with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) print ("y in sj3 is:\n" ,sess.run(y, feed_dict={ x:[[0.7 ,0.5 ],[0.2 ,0.3 ],[0.3 ,0.4 ],[0.4 ,0.5 ]] }))
打印结果:[[3.0904665] [1.2236414] [1.7270732] [2.2305048]]