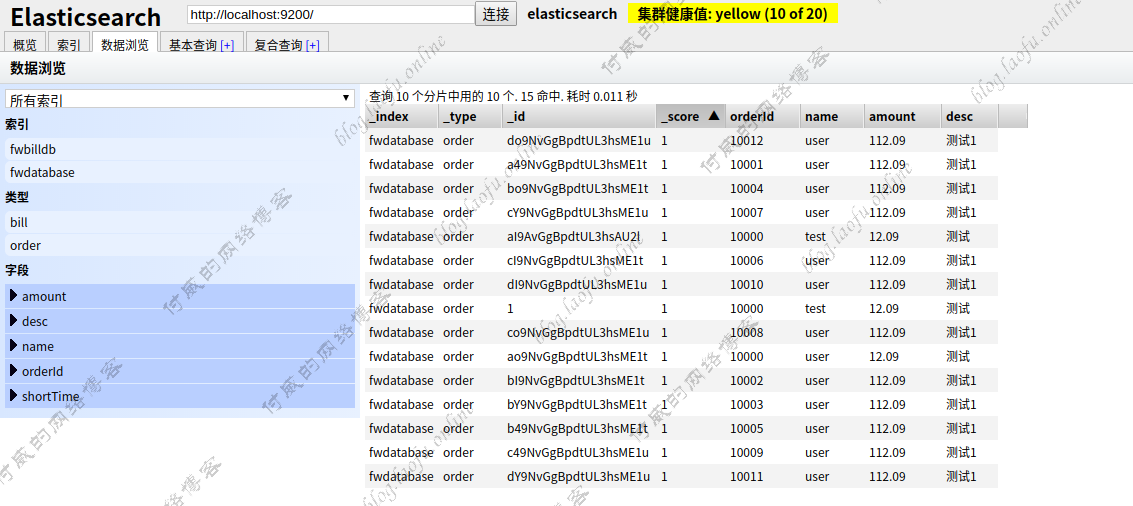
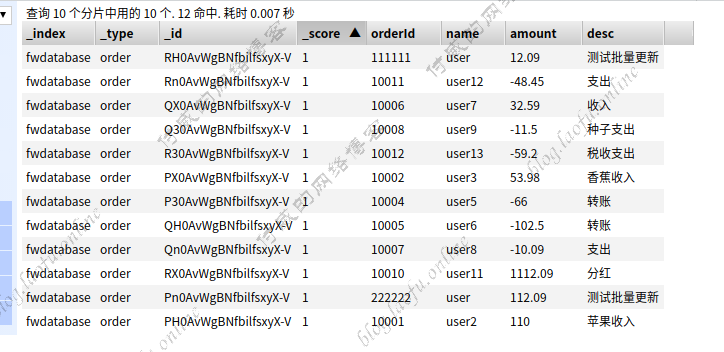
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
{"index":{}}
{"shortTime":"2019-01-05","orderId":"10000","name":"user1","amount":12.09,"desc":"水果收入"}
{"index":{}}
{"shortTime":"2019-01-08","orderId":"10001","name":"user2","amount":110.00,"desc":"苹果收入"}
{"index":{}}
{"shortTime":"2019-01-09","orderId":"10002","name":"user3","amount":53.98,"desc":"香蕉收入"}
{"index":{}}
{"shortTime":"2019-01-08","orderId":"10003","name":"user4","amount":-53.09,"desc":"支出"}
{"index":{}}
{"shortTime":"2019-01-18","orderId":"10004","name":"user5","amount":-66.00,"desc":"转账"}
{"index":{}}
{"shortTime":"2019-01-28","orderId":"10005","name":"user6","amount":-102.50,"desc":"转账"}
{"index":{}}
{"shortTime":"2019-01-08","orderId":"10006","name":"user7","amount":32.59,"desc":"收入"}
{"index":{}}
{"shortTime":"2019-01-08","orderId":"10007","name":"user8","amount":-10.09,"desc":"支出"}
{"index":{}}
{"shortTime":"2019-01-06","orderId":"10008","name":"user9","amount":-11.50,"desc":"种子支出"}
{"index":{}}
{"shortTime":"2019-01-08","orderId":"10009","name":"user10","amount":305.49,"desc":"其他入账"}
{"index":{}}
{"shortTime":"2019-01-04","orderId":"10010","name":"user11","amount":1112.09,"desc":"分红"}
{"index":{}}
{"shortTime":"2019-01-08","orderId":"10011","name":"user12","amount":-48.45,"desc":"支出"}
{"index":{}}
{"shortTime":"2019-01-06","orderId":"10012","name":"user13","amount":-59.20,"desc":"税收支出"}
|