为什么又要折腾?
原来的博客用的是 Jekyll 搭建的,jekyll 是基于 ruby 开发的。现在的 ruby 维护太少了,我碰到的问题,一直没有很好的解决方案
老版本不支持 golang 语言的高亮,即使换了 highlightjs 的版本也不行,后续很多博客都无法更新
觊觎 next 主题有一段时间了,也想换成 netx 主题。
耗费了半天时间,踩了不少坑。还有很多优化,没有时间弄,后续再不上
以后博客这东西 还是少折腾。
找到 Method 的 DescriptionIndex 的属性,找到对应的描述,例如:
1 | public class AddMain { |
这个例子中的 java 代码,add 方法对应的代码是 (II)I,最后一个 I 代表返回值,这个代表两个整型的参数.
1 | private static int add(int a, int b,String c,boolean d) { |
同样,(IILjava/lang/String;Z)I 代表有4个参数,字符串的表示是:Ljava/lang/String;,解析比较特殊。
在运行一段 java 代码的时候需要经过编译,验证,加载和运行,具体如下图:
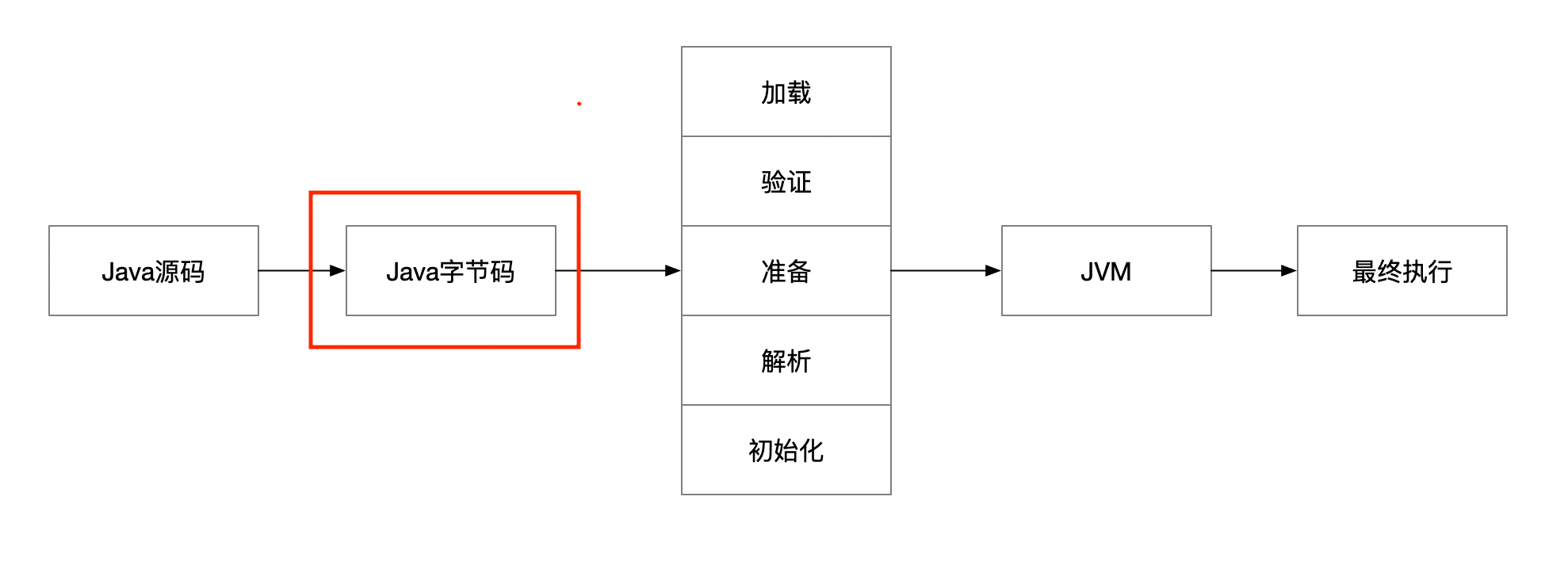
对于 Java 源码变成字节码的编译过程,我们暂且跳过不讨论。
想弄清楚 java 代码的运行原理,其实本质就是 java 字节码如何被 jvm 执行。
在学习的JVM的时候,最重要的是认识JVM的指令,JVM指令很多,为了方便记忆,可以根据前缀和功能进行分类:
例如:nop指令代表是一个空指令,JVM收到指令后,什么都不用做,等待下一个指令。
访问者模式是一种对象和对象的访问者分开的一种设计模式,在一个对象稳定的情况下,使用访问者模式可以更好的扩展对数据的访问。 相当于是我们在对象里面安插了一个“眼”,这个眼能够被外面实现,然后能拿到当前对象的各个属性。
window下解决端口进程的命令:
netstat -ano | findStr 8080 找到对应的线程pid,比如10025taskKill /F /pid 10025杀死线程在23种设计模式中,装饰者模式在游戏开发的过程中,使用的很是频繁。因为这个设计模式,把所有的业务的逻辑封装的对应的实体类中,从而为主流程减负了。首先看下一个应用场景
我们都知道有一款经典游戏90坦克,这个游戏中,玩家坦克来操作坦克打击AI敌人,在没打死一个红色坦克就会掉下来一个装备,这个装备可以提升移动速度,增加攻击力。
Update your browser to view this website correctly.&npsb;Update my browser now
