启动zookeeper
1 | $ bin/zkServer.sh start conf/zoo.cfg & |
启动Kafka
我们启动两个实例:
1 | $ bin/kafka-server-start.sh -daemon config/server.properties |
1 | $ bin/zkServer.sh start conf/zoo.cfg & |
我们启动两个实例:
1 | $ bin/kafka-server-start.sh -daemon config/server.properties |
未选择的路(罗伯特·弗罗斯特)
黄色的树林里分出两条路
可惜我不能同时去涉足
我在那路口久久伫立
我向着一条路极目望去
Kafka是基于partition的模型,在消费的时候,消费者会和kafka建立一个绑定的关系。假设有一个topic有3个partition:P1,P2,P3,同时有一个消费group对应有3个消费者:C1,C2,C3,则消费会建立一个P1-C1,P2-C2,P3-C3的关系。
broker:集群中的每一台服务器,称为Broker
topic或者subject:队列名
partition:一个队列中的消息可以存储到多台broker上面,一个broker中的分区,称为partition
EventBus 是Guava的一个发布订阅的模型,先看一个简单的实现:
定义一个Event的消息传递对象
1 |
|
定义一个Listener
1 | public class EventListener { |
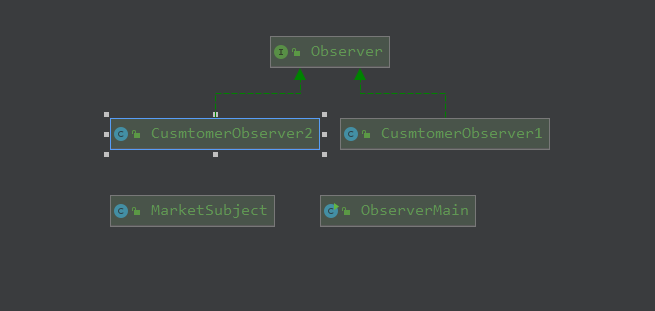
观察者模式是一个消息的派发的模式,是把被观察者的状态能够及时的通知给观察者。
比如一个超市的打折了,需要把消息通知给每一个超市的顾客,这样就可以把超市作为一个被观察者,而顾客是观察者。
观察者模式实现的类图如下:
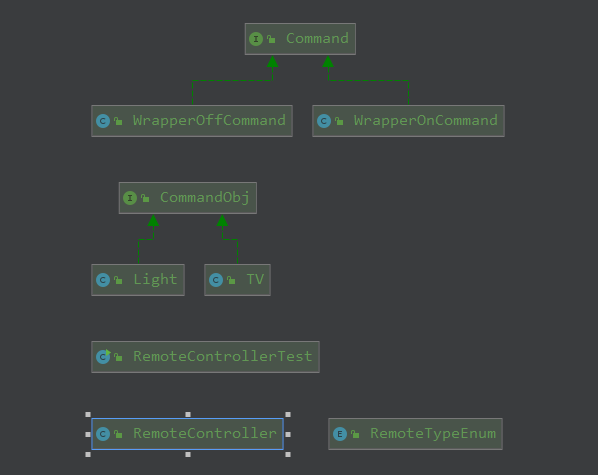
命令模式是把对象的操作方法分成一个命令,分别去执行。在分布式环境中,熔断和降级组件使用的设计模式就是命令模式。
为了了解什么是设计模式,可以类比下设计一个万能遥控器的设置,遥控器只负责一个方法的调用,真正的方法实现都在对应的电器上面。
使用的时候,只需要对对应的命令和实体进行注册下就可以了。具体的设计类图如下:
在操作系统中,从内核的形态区分,可以分为内核态(Kernel Space)和用户态(User Space)。
在传统的IO中,如果把数据通过网络发送到指定端的时候,数据需要经历下面的几个过程:
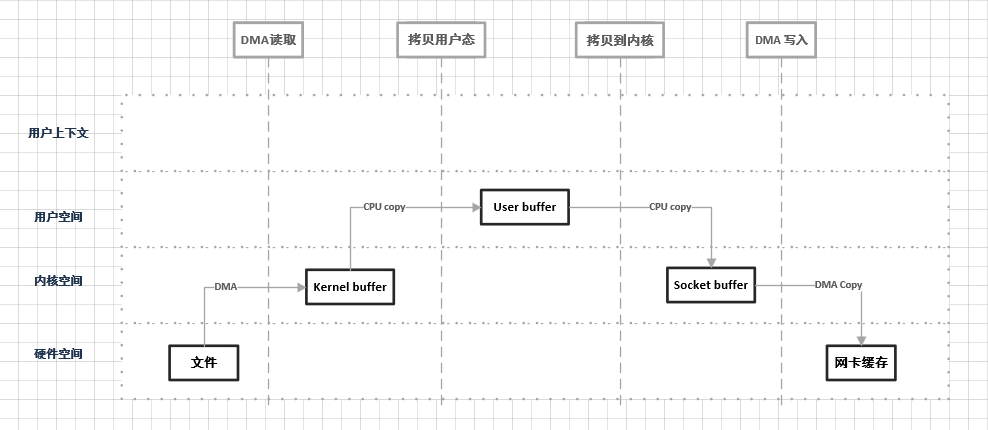
CPU Copy,内存会有内核态写入用户的缓存区。 对于磁盘的读写分为两种模式,顺序IO和随机IO。 随机IO存在一个寻址的过程,所以效率比较低。而顺序IO,相当于有一个物理索引,在读取的时候不需要寻找地址,效率很高。
网上盗了一个图(侵权删)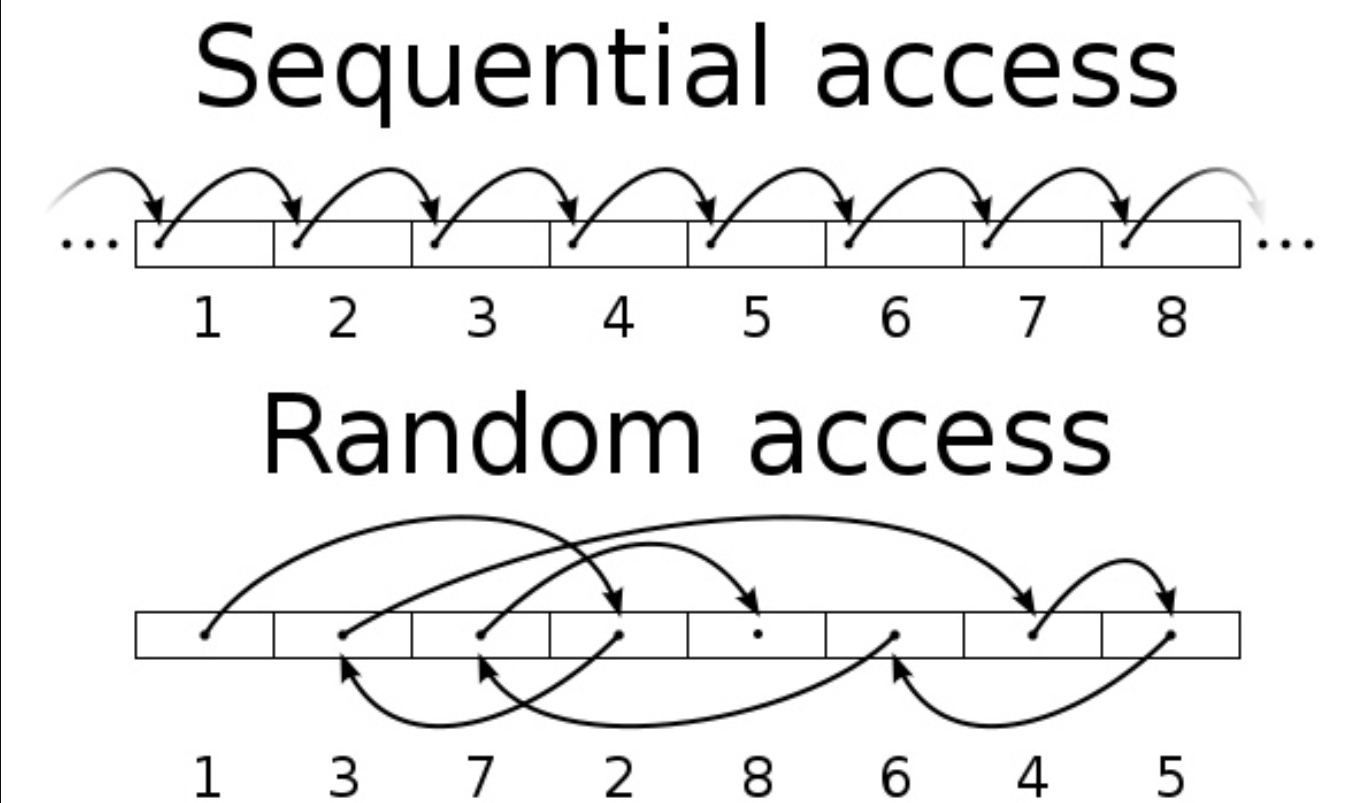
Update your browser to view this website correctly.&npsb;Update my browser now

