前端的开发人员应该都知道sublime的神器,今天就说说如何使用sublime结合markdown快速写博客。
添加Snippets
在使用jekyll写博客的时候开篇都需要去写一个头部,内容如下:
layout: post
title:xxxxx
date:xxxxxxx
author:xxxx
```
对于这个固定格式我们可以定义一个Snippets,具体的步骤如下:
1. 在sublime中的** Tools-->Developer-->New Snippets.. **
``` bash
<snippet>
<content><![CDATA[
Hello, ${1:this} is a ${2:snippet}.
]]></content>
<!-- Optional: Set a tabTrigger to define how to trigger the snippet -->
<!-- <tabTrigger>hello</tabTrigger> -->
<!-- Optional: Set a scope to limit where the snippet will trigger -->
<!-- <scope>source.python</scope> -->
</snippet>
上面代码片段包含了sublime在什么时候插入什么内,详细参考官方文档Snippets{:target=”_blank”}
content
- Hello, ${1:this} is a ${2:snippet}. 要的显示的文本
其中的${}符号是tab索引占位,${1:time},说明此处是tab第一个占位,默认值是time
tabTrigger
- <tabTrigger>hello</tabTrigger> 要触发的版本
scope
- <scope>source.python</scope> 在那个类型文件触发
下面是我根据我自己的需要来创建的snippets,在markdown和html模式下,输入blog+tab 就直接显示上面的内容.
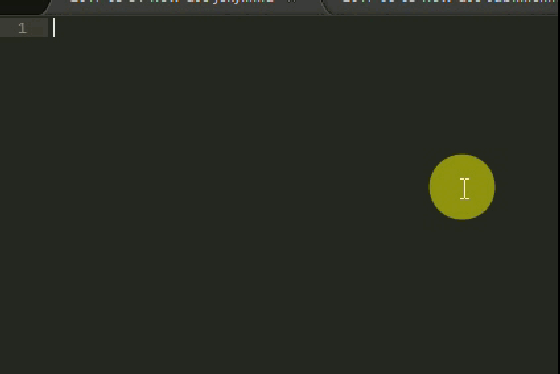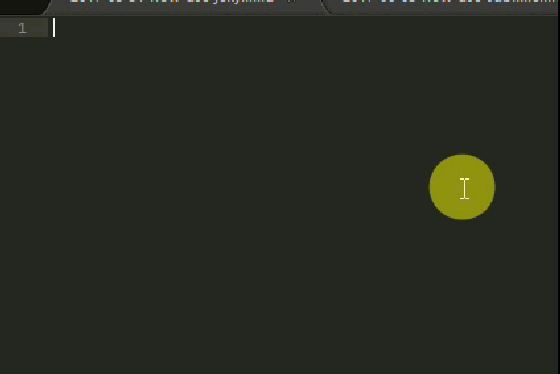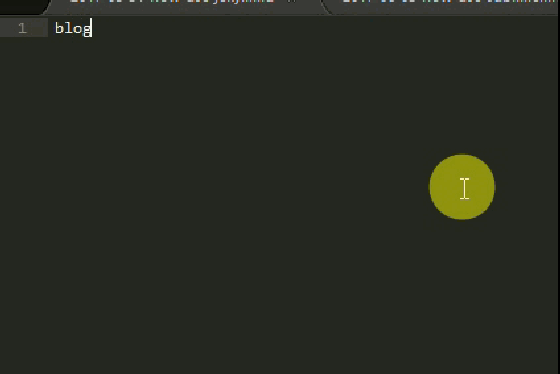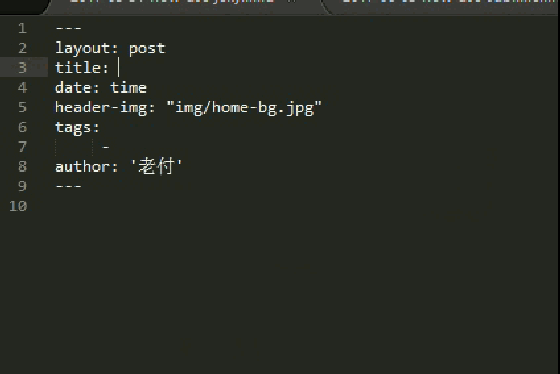
<snippet>
<content><![CDATA[
---
layout: post
title: ${1}
date: ${2:time}
header-img: "img/home-bg.jpg"
tags:
- ${3}
author: '付威'
---
${4}
]]></content>
<!-- Optional: Set a tabTrigger to define how to trigger the snippet -->
<tabTrigger>blog</tabTrigger>
<!-- Optional: Set a scope to limit where the snippet will trigger -->
<scope>text.html.markdown,text.html</scope>
</snippet>
注意:创建完成后,一定要保存成.sublime-snippet,效果如下:
自定义编译系统
当写完一个博客的时候,可以执行jekyll server去在本地查看效果,当文件发生发动的时候,jekyll也会自动重新最新的博客。但如果要把数据上传到github上面,不得不输入以下几个命令:
git add .
git commit -m 'update'
git push origin gh-pages
当完成上传之后,还要手动打开网站去查看最终的博客效果。下面就把这个过程做成一个sublime编译的系统,首先我先演示下windows下如果自动化完成这个功能。
首先根据上面的功能创建一个批处理文件,文件为post.bat 结尾:
@echo off
cd ..
git add .
git commit -m 'update'
git push origin gh-pages
start http://blog.laofu.online
在_posts目录下面运行的时候,可以看到,脚本可以自动把脚本 传入到git上面,同时默认的浏览器打开博客。
新建一个编译系统 Tools–>Build System–>New Build System .. ,sublime会提供一个默认的数据,详细配置参见Build Systems – Configuration{:target=”_blank”} ,此处我们可以修改成如下的配置:
{
"cmd": ["处理文件的目录\\post.bat", "$file"],
"working_dir": "$file_path",
"selector": "text.html.markdown"
}
配置修改完成后,保存成.sublime-build文件。当我们写好博客后,按Ctrl+B的时候,sublime会自动调用处理文件,完成上传发布工作。