window下解决端口进程的命令:
netstat -ano | findStr 8080找到对应的线程pid,比如10025- 使用
taskKill /F /pid 10025杀死线程
window下解决端口进程的命令:
netstat -ano | findStr 8080 找到对应的线程pid,比如10025taskKill /F /pid 10025杀死线程在一个服务器的集群上面,服务器的CPU长时间居高不下,响应的时间也一直很慢,即使扩容了服务器CPU的下降效果也不是很明显。
对于CPU过高的原因,可以总结到以下原因:
太多的循环或者死循环
加载了过多的数据,导致产生了很多的大对象
产生了过多的对象,GC回收过于频繁(如:字符串拼接)
对于上面的情况,难点不是优化代码,难点在于定位到问题的所在,下面我们就用Dump抓包的方式来定位到问题的所在。介绍这个内容之前,我们要先回顾下.Net中垃圾回收的基础知识和一个工具的准备。
代码显示调用System.GC的静态方法
windows报告低内存情况
CLR正在卸载AppDoamin
CLR正在关闭
CLR将对象分为大对象和小对象,认为大于85000字节或者更大的字节是大对象,CLR用不同的方式来对待大对象和小对象:
大对象不是在小对象的地址空间分配,而是在进程地址空间和其他地方分配
GC不会压缩大对象,在内存中移动他们的代价过高,但这样会造成地址空间的碎片化,以至于会抛出OutOfMemeryException 异常。
大对象总是在第二代回收。
下载[windbg文件](dbg_amd64_6.12.2.633.msi)
相关DLL准备clr.dll和sos.dll,(都在对应.Net版本安装目录下面,我的安装目录在C:\Windows\Microsoft.NET\Framework64\v4.0.30319)
一个cpu运行的较高的时期的DUMP文件(下面会说如何获取)
准备测试代码,此处为了演示方便,简单了写了一个有潜在问题的代码:
1 | public class Common |
我们知道在字符串的拼接的时候,每一个字符串都是一个对象,拼接后又产生了一个新对象,所以在GetString这个方法中会有大量的GC操作,下面我们就调用下这个代码,看下CPU的情况,为了模拟并发情况,我们开多个标签,每个标签每1s秒中刷新一次。
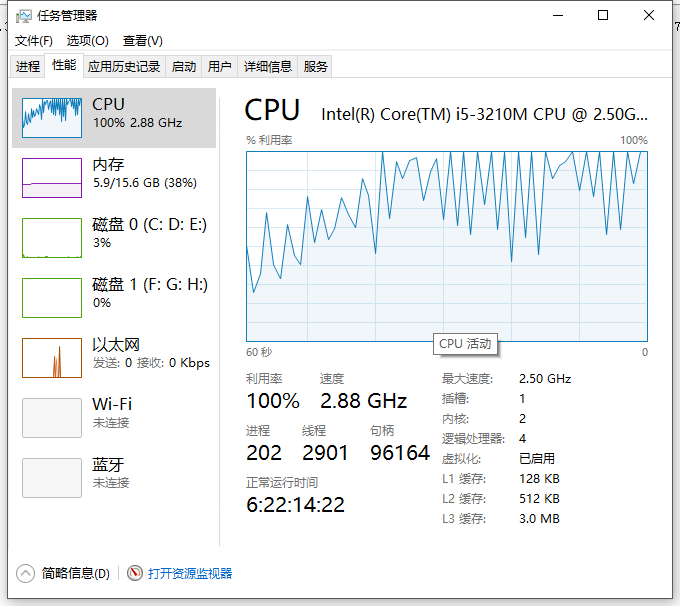
在任务管理器中选择应用程序池对应的w3wp.exe,右击–>创建转储文件。创建完成后,会提示出指定的路径

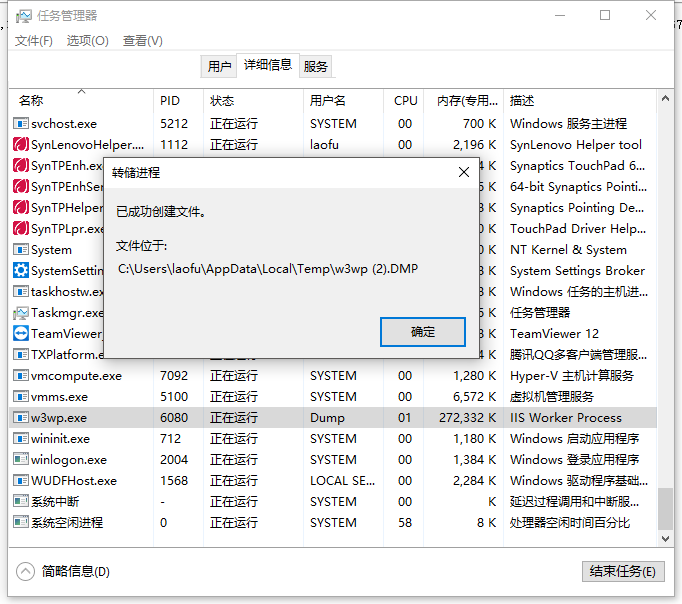
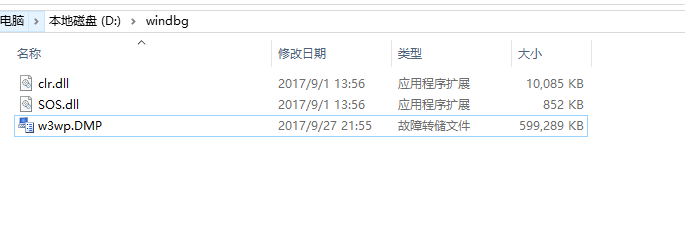
根据上面的步骤,我们准备我们分析的文件如下:
打开windbg,加载对应的dump文件

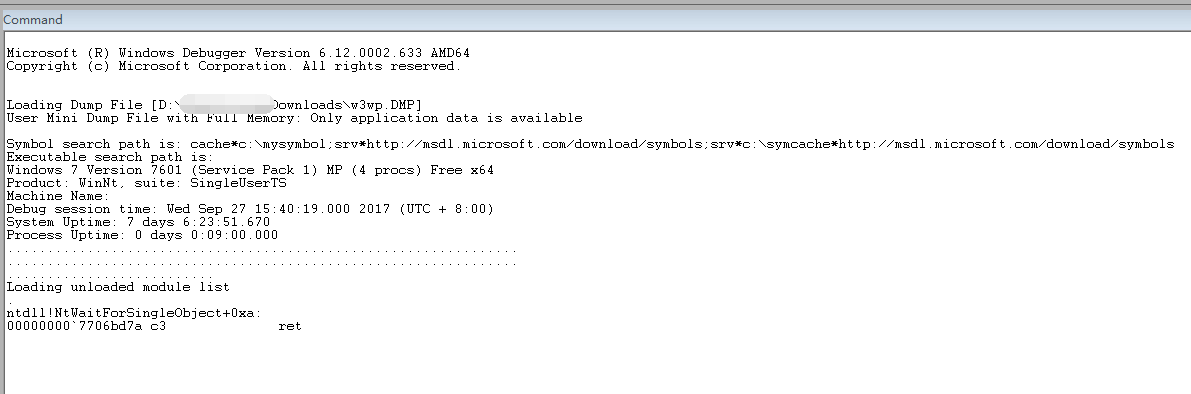
配置Sysmbol,添加”cachec:\mysymbol;srvhttp://msdl.microsoft.com/download/symbols“
load sos.dll和clr.dll,命令如下:
.load D:\windbg\sos.dll
.load D:\windbg\clr.dll
运行命令!threadpool 显示有关托管线程池的信息,其它一些SOS 调试扩展命令.

运行!runaway 查询cpu占用时长比较长的几个线程Id
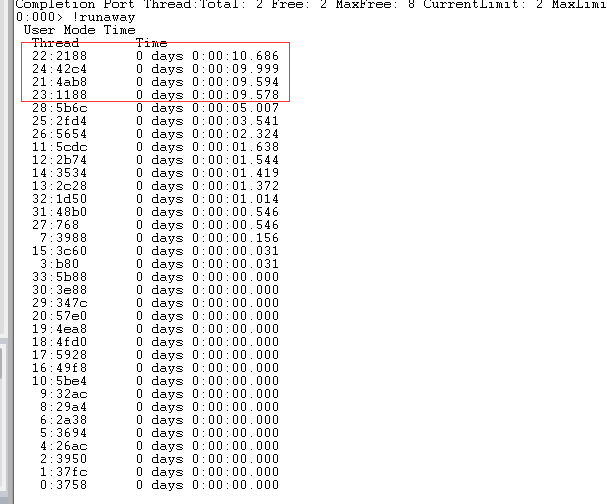
运行~22s (进入线程查看),kb(查看对应的调用)

运行~* kb 查看所有线程的堆栈调用

在上面搜索GC和大对象出现的线程 (ctrl+f搜索:GarbageCollectGeneration和allocate_large_object )

可以看到定位触发GC的线程是31号线程
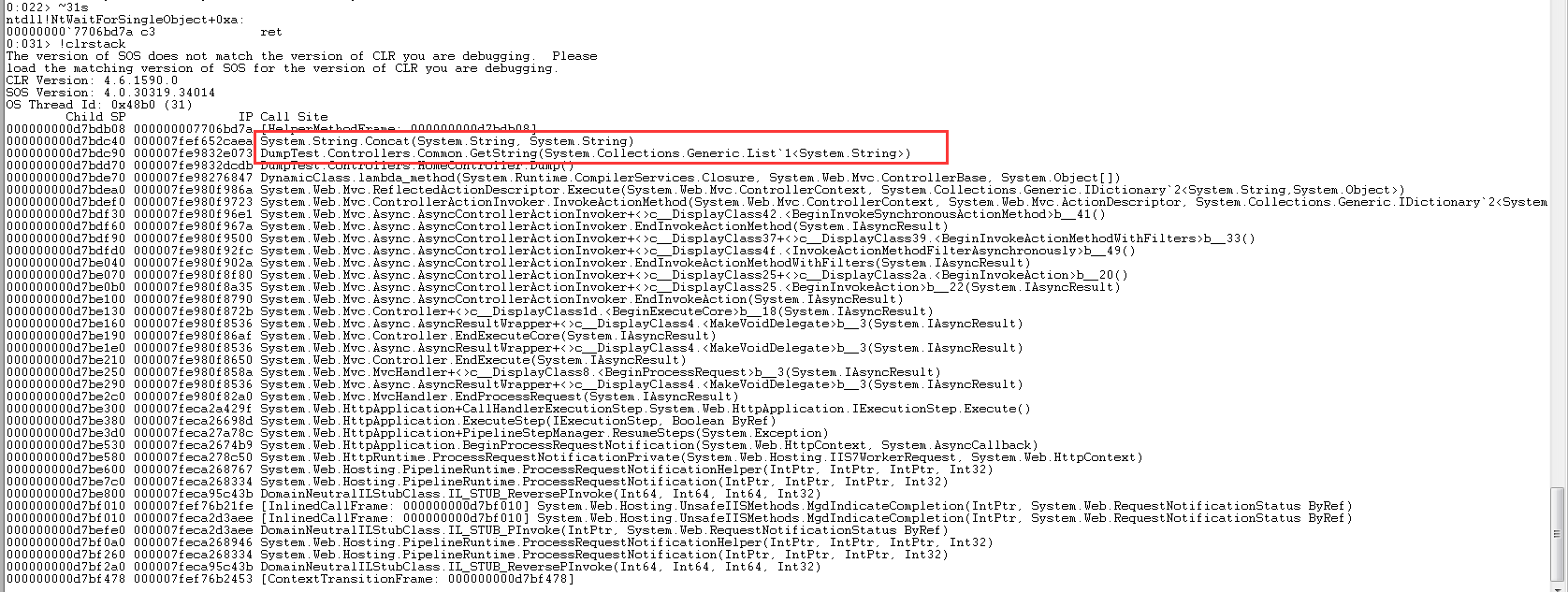
运行命令~31s 进入31线程,再运行!clrstack查看堆栈调用,最终可以定位到出问题的代码,是由于字符串的拼接导致大量的对象产生,从而触发了GC。
说到正则,可能很多人会很头疼这个东西,除了计算机好像很难快速的读懂这个东西,更不用说如果使用了。下面我们由浅入深来探索下正则表达式:
ps:此文适用于还有没有入门正则表达基础的读者
字符编码探密--ASCII,UTF8,GBK,Unicode
在计算机的“原始社会”,有人想把日常的使用的语言使用计算机来表示, 我们知道在计算机的世界里面,只有0和1,为了解决尽量多的去表示字符,最终他们决定用8位0和1(一个字节)来表示字符,并且规定当机器读到这几个数据的时候,做出动作或者打印出指定的字符:
Update your browser to view this website correctly.&npsb;Update my browser now
