TOP 命令的含义
TOP 命令是常用的 Linux 性能监控的命令,执行后,界面如下:

第一行
1 | top - 14:09:04 up 3 days, 21:20, 0 users, load average: 0.52, 0.58, 0.59 |
当前时间(date)、系统已运行时间(last reboot)、当前登录用户的数量(who )、最近5、10、15分钟内的平均负载
TOP 命令是常用的 Linux 性能监控的命令,执行后,界面如下:
1 | top - 14:09:04 up 3 days, 21:20, 0 users, load average: 0.52, 0.58, 0.59 |
当前时间(date)、系统已运行时间(last reboot)、当前登录用户的数量(who )、最近5、10、15分钟内的平均负载
MyCat 是基于服务器代理模式的数据库分库的中间件,原理是对 SQL 进行转发,具体的架构图如下:
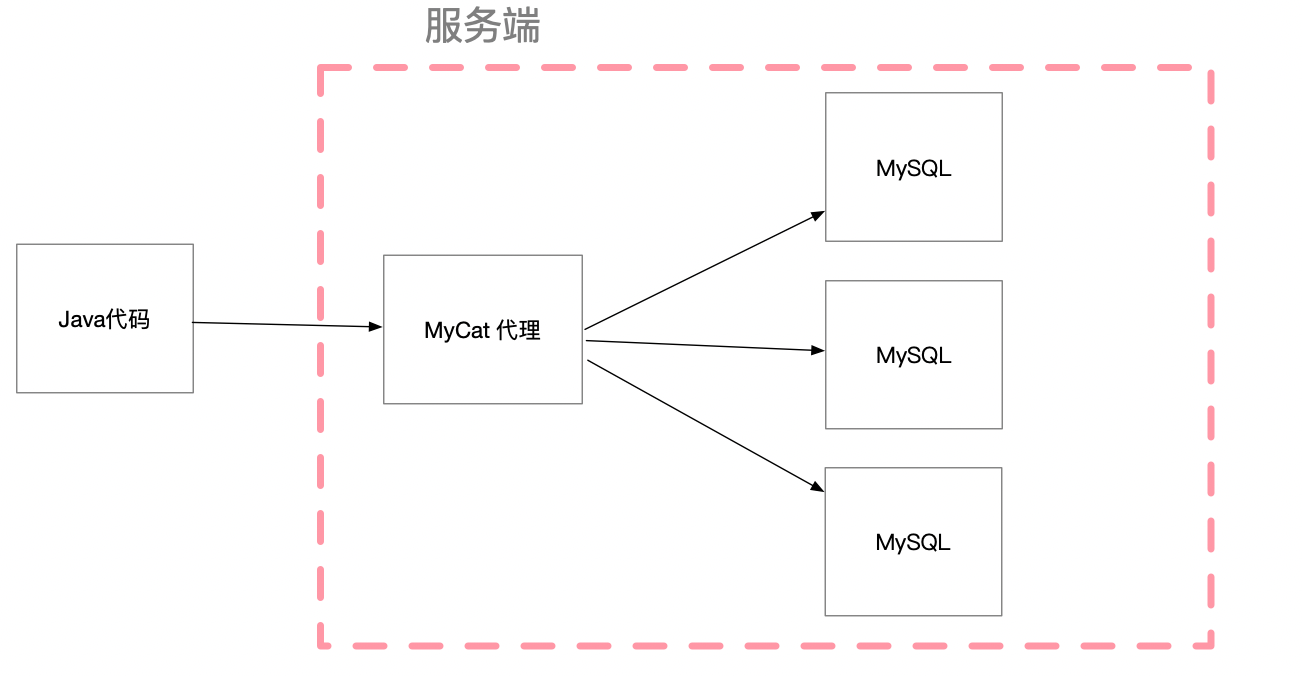
我们知道,数据的拆分必然会对事物的原子性带来影响,那如果保证在分库的同时,又能保证事务的原子性呢?
除了上面的几个明显的问题外,还有索引的选择问题。MySQL 在执行一段 sql 的时候,会先决定使用哪一个索引,如果 选了一个性能比较差的索引,即使走了索引,也会带来性能问题。
对上面的第 4 条做一个例子说明:
最近又碰到的 oom 的问题,一直在尝试定位中,由于现实使用的 G1 的垃圾回收器。所以今天打算线上的排查历程和方案查询出来。
1 | -Xmx1024m 最大堆内存 |
事务要保证 ACID 的完整性必须依靠事务日志做跟踪:
每一个操作在真正写入数据数据库之前,先写入到日志文件中
如要删数据会先在日志文件中将此行标记为删除,但是数据库中的数据文件并没有发生变化。
只有在(包含多个 sql 语句)整个事务提交后,再把整个事务中的 sql 语句批量同步到磁盘上的数据库文件。
在事务引擎上的每一次写操作都需要执行两遍如下过程:
先写入日志文件中
写入日志文件中的仅仅是操作过程,而不是操作数据本身,所以速度比写数据库文件速度要快很多。
然后再写入数据库文件中
写入数据库文件的操作是重做事务日志中已提交的事务操作的记录
下载包
1 | https://repo.huaweicloud.com/mysql/Downloads/MySQL-8.0/mysql-8.0.20-linux-glibc2.12-x86_64.tar.xz |
解压
1 | tar -xvf mysql-8.0.20-linux-glibc2.12-x86_64.tar.xz |
上篇博客说了 MVCC 解决了 MySQL 在可重复的隔离情况下幻读的问题,这篇博客主要探讨下,在修改的时候,如何解决幻读的问题。
MySQL 在控制并发的时候,同样采用了锁的机制。从读写上面分,有读写和写锁,从结构上分,有行锁和表锁.行锁又分为行锁、间隙锁和 Next Key
读锁 :共享锁 ,S 锁
写锁:排它锁 ,X 锁
select :不加锁,加锁后,也可以使用 select 查询数据
数据库的事务一共有四个特性:
原子性:代表事务是一个动作,要么同时成功,要么同时失败一致性:事务开始和结束数据完整性没有发生破坏隔离性:两个事务动作相互独立,不受干扰持久性:事务完成后,能够保存到数据库。那 MySQL 是如何保证这个四个特性的呢?
为了弄明白这几个特性,我们需要先看下事务的隔离级别。
在代号为 C-137 的地球上,Rick 发现如果他将两个球放在他新发明的篮子里,它们之间会形成特殊形式的磁力。Rick 有 n 个空的篮子,第 i 个篮子的位置在 position[i] ,Morty 想把 m 个球放到这些篮子里,使得任意两球间 最小磁力 最大。
已知两个球如果分别位于 x 和 y ,那么它们之间的磁力为 |x - y| 。
给你一个整数数组 position 和一个整数 m ,请你返回最大化的最小磁力。
Update your browser to view this website correctly.&npsb;Update my browser now
