使用Mnist的数据集实现对手写数字识别
感慨下,学了这么久终于有能有点实战的东西了,这篇文章本想写于2019-04-14,可是担心会对学习的进度产生影响,就一直拖后。所以就再今天(2019-04-24)开始去写这篇实战的文章。
目标
写这篇博客的目的就是为了写一个识别手写程序的方案,首先我们准备了mnist(mnist数据集)的数据集,和一张手写的图片
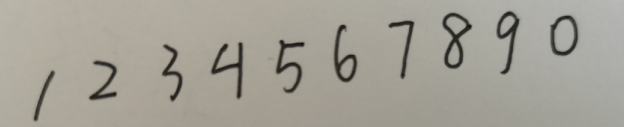 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}
为了测试,增加了一些干扰线:
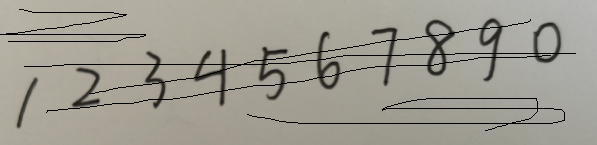 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}
我们知道,在mnist的数据集中,是对单个28*28像素图片进行处理,而且是黑底白字的数字图片,所以为了能够使用mnist的数据样本训练,我们也需要对手写的图片处理。
具体的处理方法我们可以分为:
1.二值化
2.去噪声
3.裁剪
4.缩放28*28的图像
5.训练样本
6.识别结果
二值化和去噪声
对于这个图片的二值化可以使用opencv相关处理模块,二值化是直接把图片编程只有黑白两种颜色的图:
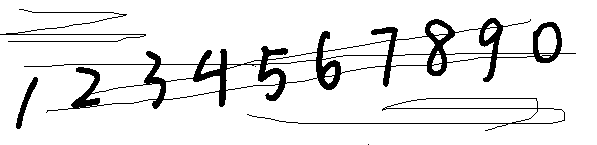 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}
我们可以看到上面有几个 使用均值模糊可以去除干扰线和噪点:
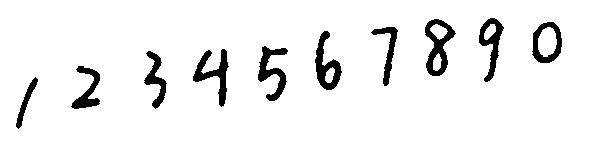 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}
对模糊后的图片再进行二值化,得到结果如下:
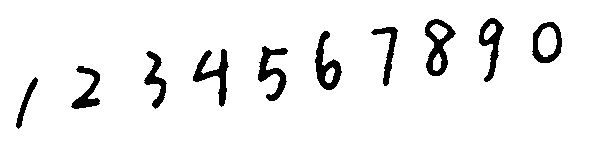 {:height=”600px” width=”600px”}
{:height=”600px” width=”600px”}
对应的代码如下:
1 | import cv2 as cv |
对图片进行裁剪 ,分别按行和列去做累加,找到平均值不等于255的点,找出最小值和最大值,对应的图片裁剪的开始和结束。
1 | def corp_img(image): |
截取后保存后的图片结果为:

mnist的样本数据结果:

对比样本数据结果:

通过对比,我们可以发现截取后的图片没有边框,是白底黑字,分辨率也和mnist的样本数据不同,为了能够使用mnist的数据模型,需要对图片做进一步填充,缩放,反色:
1 | # 反色函数 |
经过处理后的图片效果如下,基本与mnist的数据样本格式一致:

训练模型
原理: 要被识别和训练的模型是一个28*28的图片矩阵,共有784个元素。而最终我们需要得到的结果是一个1x10的数组,所以我们对原来的图片转换成1x784的一维数组X,根据前向传播的神经元模型:,可以知道W是784*10的矩阵,b是一个1*10的矩阵。我们的训练步骤如下:
- 随机获得
784*10矩阵W和偏执项1*10的矩阵b - 利用神经元的函数关系,并使用激活函数
relu,计算出一个不准确的y - 对于输入的正确结果y,定义为y_,使用交叉熵的方式计算损失函数
- 使用正则化方式防止模型过拟合
- 使用指数衰减的学习率,模型更好的变动
- 使用反向传播的训练方法,减少loss函数的损失
- 对所有的参数使用滑动平均,更准确的确定模型参数
- 读取mnist的数据,喂入神经网络,开始训练
神经网络的代码如下:
前向传播代码:minst_forward.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# coding:utf-8
import tensorflow as tf
INPUT_NODE=784
OUTPUT_NODE=10
LAYER1_NODE=500
#定义输入输出参数和前向传播过程
def get_weight(shape,regularizer):
w=tf.Variable(tf.random_normal(shape),dtype=tf.float32)
if regularizer!=None:
tf.add_to_collection("losses",tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b=tf.Variable(tf.constant(0.01,shape=shape))
return b
def forward(x,regularizer):
w1=get_weight([INPUT_NODE,LAYER1_NODE],regularizer)
b1=get_bias([LAYER1_NODE])
y1=tf.nn.relu(tf.matmul(x,w1)+b1)
w2=get_weight([LAYER1_NODE,OUTPUT_NODE],regularizer)
b2=get_bias([OUTPUT_NODE])
y=tf.matmul(y1,w2)+b2
return y
反向传播代码:minst_backward.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73# coding:utf-8
import tensorflow as tf
import minst_forward
import os
from tensorflow.examples.tutorials.mnist import input_data
BATCH_SIZE = 200
LEARNING_RATE_BASE = 0.1
LEARNING_RATE_DECAY = 0.99
REGULARIZER = 0.0001
STEPS = 100000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = "./model/"
MODEL_NAME = "minst_model"
def backword(minst):
x = tf.placeholder(tf.float32, (None, minst_forward.INPUT_NODE))
y_ = tf.placeholder(tf.float32, (None, minst_forward.OUTPUT_NODE))
y = minst_forward.forward(x, REGULARIZER)
global_step = tf.Variable(0, trainable=False)
# 使用交叉熵的形式定义损失函数
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
#正则化防止过拟合
loss = cem + tf.add_n(tf.get_collection("losses"))
# 使用指数衰减的学习率,实现更好的学习率
learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE,
global_step,
minst.train.num_examples/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
# 使用反向传播训练方法,以减小loss值为优化目标
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
# 对所有的参数都使用滑动平均,更准确的定义模型。
ema=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
emp_op=ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step,emp_op]):
train_op=tf.no_op(name="train")
saver=tf.train.Saver()
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
ckpt=tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
for i in range(STEPS):
xs,ys =minst.train.next_batch(BATCH_SIZE)
_,loss_value,step=sess.run([train_op,loss,global_step],feed_dict={x:xs,y_:ys})#喂入神经网络数据
if i%1000==0:
print("After %d training step(s),loss on training batch is %g."%(step,loss_value))
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
def main():
minst=input_data.read_data_sets("./data",one_hot=True)# 读取mnist的数据
backword(minst)
if __name__=="__main__":
main()
运行backword.py的程序,使用mnist的数据,进行10w的训练,得到数据模型如下:
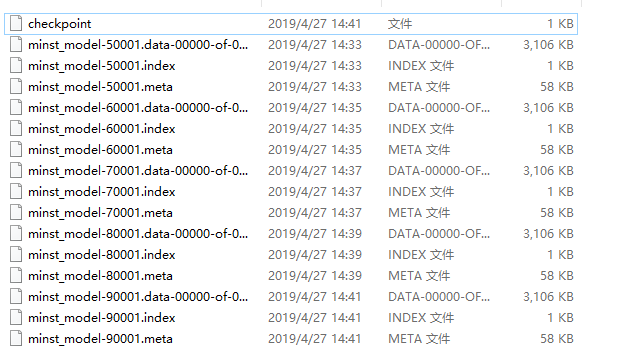
利用模型获得最大可能的预测值,代码如下:
1 | import imageUtils |
识别结果如下:
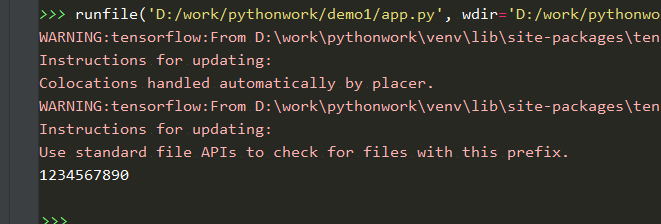
我们再输入一个正常的手写图片:
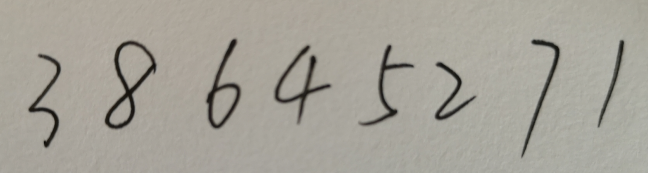
输出结果:
识别大部分数据正确,还有有识别错误的现象,因为训练的模型的差异和训练次数过少,所以会导致识别出错的现象。