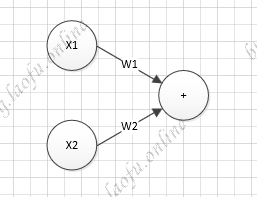
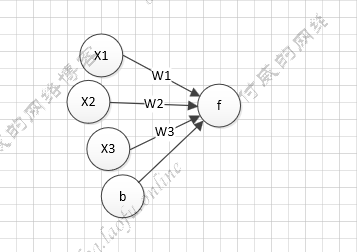
with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) STEPS=20000 for i inrange(STEPS): start=(i*BATCH_SIZE)%32 end =(i*BATCH_SIZE)%32+BATCH_SIZE sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%500==0: print ("After %d training steps,wl isL" %(i)) print (sess.run(w1)) print("final wl is:\n",sess.run(w1))
打印结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
After 17500 training steps,wl isL [[0.96476096] [1.0295546 ]] After 18000 training steps,wl isL [[0.9684917] [1.0262802]] After 18500 training steps,wl isL [[0.9718707] [1.0233142]] After 19000 training steps,wl isL [[0.974931 ] [1.0206276]] After 19500 training steps,wl isL [[0.9777026] [1.0181949]] final wl is: [[0.98019385] [1.0159807 ]]
with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) STEPS=20000 for i inrange(STEPS): start=(i*BATCH_SIZE)%32 end =(i*BATCH_SIZE)%32+BATCH_SIZE sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%500==0: print ("After %d training steps,wl isL" %(i)) print (sess.run(w1)) print("final wl is:\n",sess.run(w1))
1 2 3 4 5 6 7 8 9 10 11 12
After 18500 training steps,wl isL [[1.0232253] [1.0445153]] After 19000 training steps,wl isL [[1.0171654] [1.038825 ]] After 19500 training steps,wl isL [[1.0208615] [1.0454264]] final wl is: [[1.020171 ] [1.0425103]]