DDD 架构思考和实践
为什么要考虑学习 DDD架构
在学习 DDD 架构前,一直觉得三层架构结构在业务复杂的场景会带来很多很多的问题,但是一直都处于模糊不清的形态,无法准确的定义。直到学习了DDD 的概念。
为了更好的学习 DDD ,我们总结一下三层架构在业务复杂的场景带来的问题,首先看下正常的项目依赖图
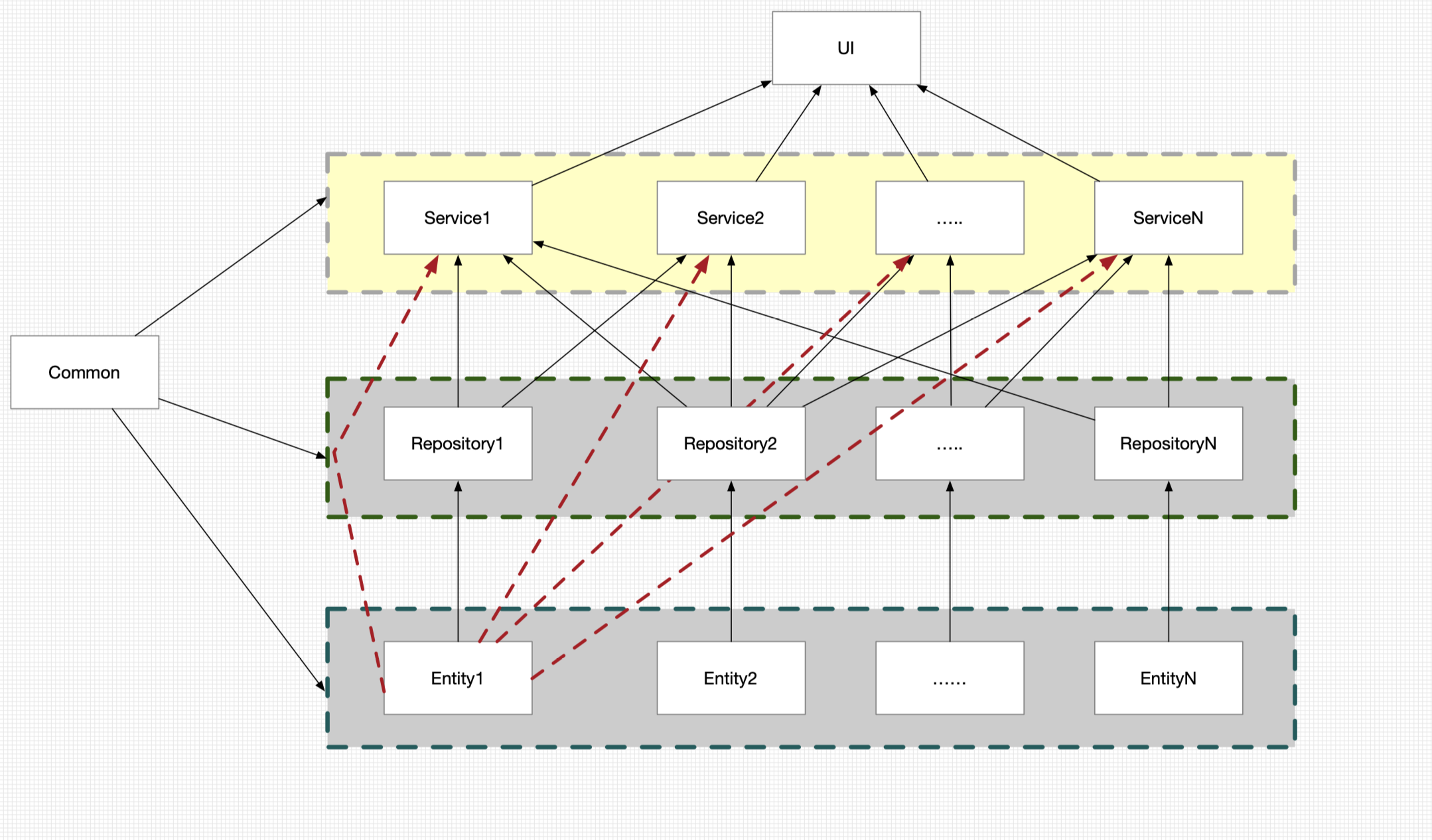
我们正常有 5 个模块,UI(application), Service,Repository,Entity 和 Common,每个层代表的含义,大家都非常清楚,这样会带来什么样的问题呢?
- Service 层对 Repository 依赖比较乱,没有明确的规则和界限
- 虽然 Repository 对 Enity 是一对一的依赖,但是由于 Service 和 Repository 的依赖的 “混乱”,导致 Entity 的引用带来同样的问题
- 每一个层级都对 Common 都有依赖,使得 Common 层从辅助层变成了核心层。
如何去处理
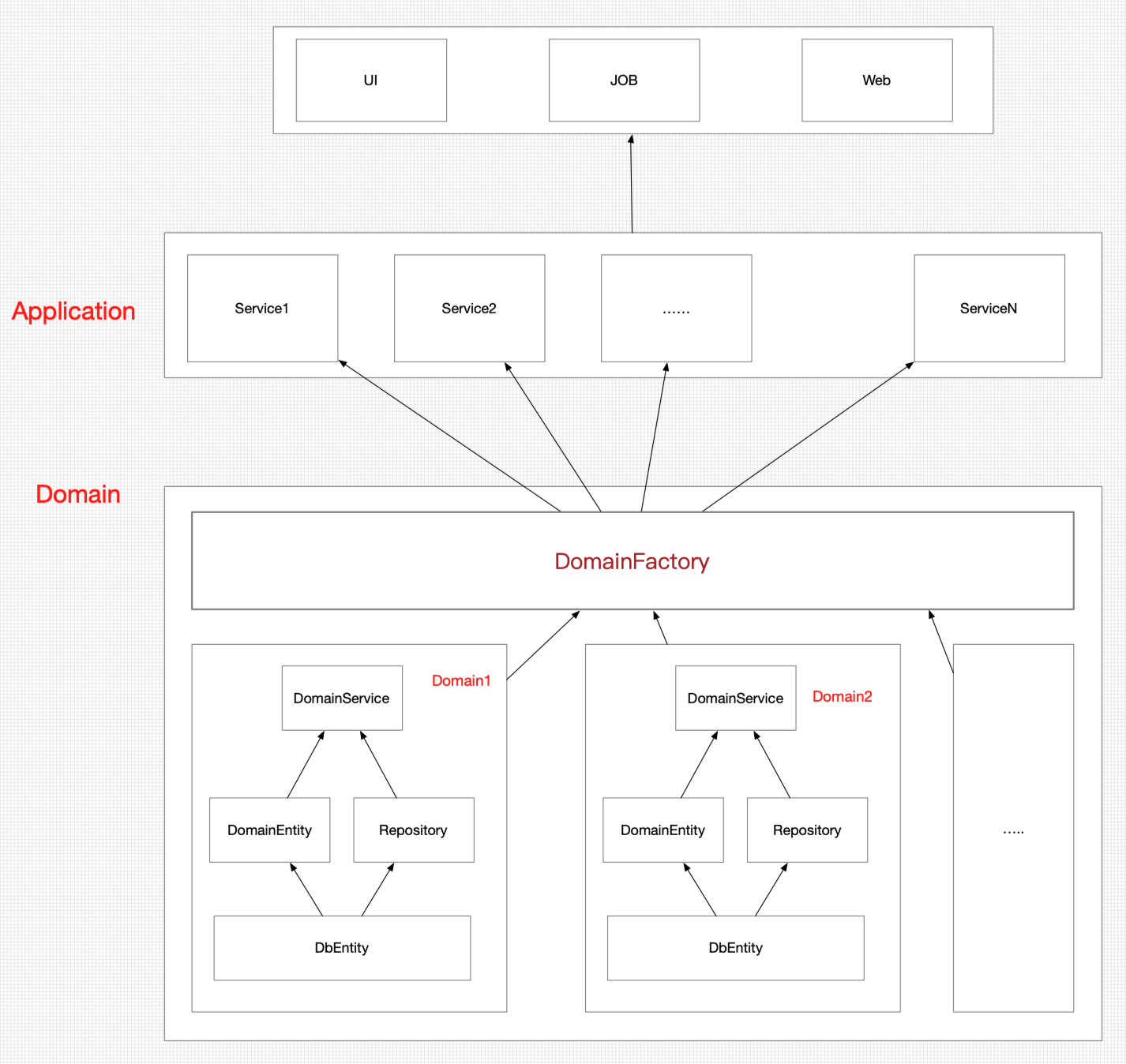
对于上面的问题,对应处理的方法如下
- 需要对服务进行设置边界,不同的业务有自己的范围,这个在 DDD 中称为 领域(domain)
- 把 Entity 层拆分,拆分为 DB 实体和领域实体,DB实体负责和数据库的映射,领域实体则可以实现领域内业务聚合实体
- 对于Common 层,可以增加基础层,把系统中可用的工具类库和访问第三方的工具类都放入基础层。
最终改写后,项目依赖会变成如下:
一个 Demo
为了更好的理解 DDD 的思想,我们搭建一个爬虫的项目来实践下,我们要爬取的数据是各个城市的疫情数据。
首先先搭建好项目的基本架构 ,一共分为 4 层:infrastructure,domain,application,UI 层
infrastructure 基础层
这个层主要负责基础类的维护和基类的存放,和业务无关,所以不多赘述

domain
Domain 负责业务的聚合,我们爬虫是城市的疫情数据,所以 主要的领域实体是 城市信息和疫情数据,他们同属一个业务 Domain。所以我们在领域内定义两个实体:CityInfo 和 CovidInfo,他们的具体字段可以根据业务需要定制,Domain 层的项目布局:
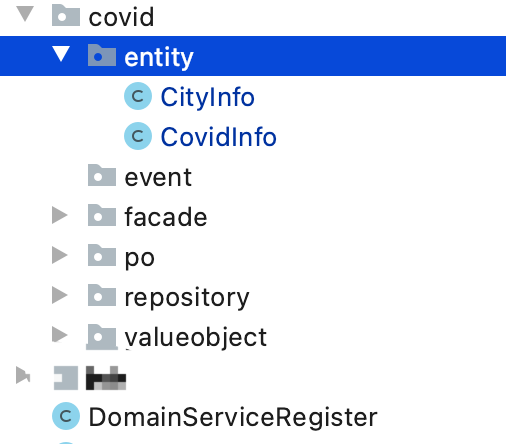
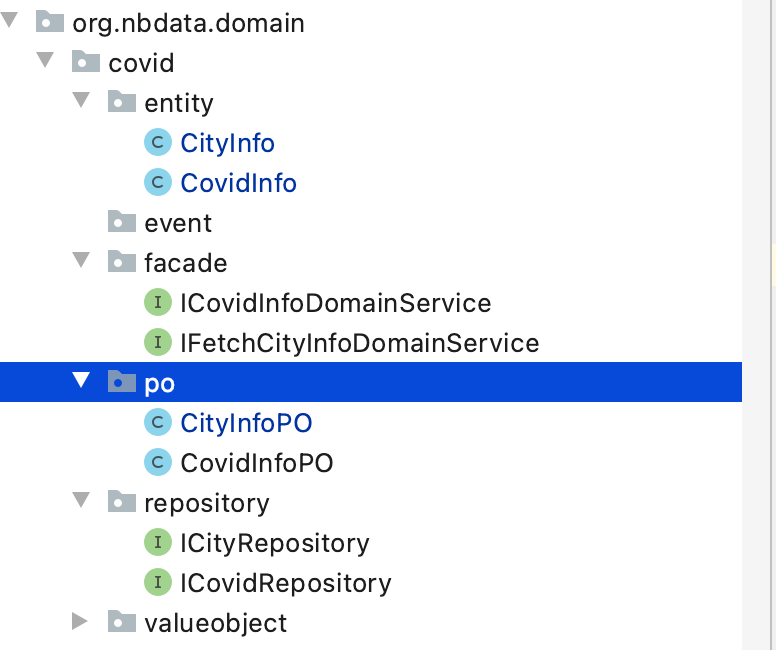
由于是爬虫的项目,考虑的数据获取的不稳定和随时更改的可能,所以我们把数据获取的实现单独抽象了一个项目,在 Domain层只是简单的写入了接口契约,具体的实现又抽象出来一个项目 infrastructure-translators。同样对于 D B访问来说,为了防止 Db 的访问有变(可能存在过度设计),也对访问 Db 做了隔离,在 Domain 仅仅定义接口实现,具体由 infrastructure-repositories 模块实现
infrastructure-translators和infrastructure-repositories
infrastructure-translators 这个是爬虫业务的实现项目,主要功能是爬虫数据爬取和转换,这个项目依赖 Domain 模块,同样在 Domain 中也使用了注入的功能实现了对 infrastructure-translators 的引用,这样实现了依赖的倒置和服务的引用的隔离(此处说法可能不太准确)。同样这个模块也实现绝大多数数据聚合的逻辑,这样 Domain 模块就变成了薄薄的一层工厂引用了
如果非爬虫的数据的访问可以直接使用 infrastructure-repositories 这个模块的类来实现数据的读取,直接使用此层的服务实现写在 Domain 层,此处与服务放在其他模块有所区别。
application
这个层是对 Domain 服务的堆叠,组合使用和事件的触发,正常情况下不会有太复杂的逻辑。

完整的项目结构图如下

框内的项目都属于 UI 层。
需要完整的项目请联系我