MySQL 事务日志
什么是事务日志?
事务要保证 ACID 的完整性必须依靠事务日志做跟踪:
每一个操作在真正写入数据数据库之前,先写入到日志文件中
如要删数据会先在日志文件中将此行标记为删除,但是数据库中的数据文件并没有发生变化。
只有在(包含多个 sql 语句)整个事务提交后,再把整个事务中的 sql 语句批量同步到磁盘上的数据库文件。
在事务引擎上的每一次写操作都需要执行两遍如下过程:
先写入日志文件中
写入日志文件中的仅仅是操作过程,而不是操作数据本身,所以速度比写数据库文件速度要快很多。
然后再写入数据库文件中
写入数据库文件的操作是重做事务日志中已提交的事务操作的记录
事务日志
事务的日志主要分为三类:redo log,undo log和binlog
日志组
在写日志的时候,单个日志如果过大,对于读写和同步都会产生影响,所以在日志变大的时候,需要对日志进行一个分组。
日志提高事务的效率和安全性保证
- 用事务日志,存储引擎在修改表的数据的时候,只需要修改其内存,再把该行为记录到持久在磁盘的事务日志中。
- 事务的日志采用的是顺序追加的方式,采用的是顺序 IO 效率很高
- 如果发生了崩溃,可以根据
redo log把数据库恢复到崩溃前的状态。
Redo log
redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo logfile),该部分日志是持久的。
- 事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲。
- 在事务提交之前,缓冲的日志都需要提前刷新到磁盘上持久化,这就常说的“日志先行”(Write- Ahead-Logging)。
- 当事务提交之后,在 Buffer Pool 中映射的数据文件才会慢慢刷新到磁盘。
- 此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据 redo log 中记录的日志,把数据库恢复到崩溃前的一个状态。
- 未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为 redo log 分配了一块连续的存储空间,以顺序追加的方式记录 Redo Log,通过顺序 IO 来改善性能。所有的事务共享 redo loge 的存储空间,它们的 Redo Log 按语句的执行顺序,依次交替的记录在一起。
持久化策略
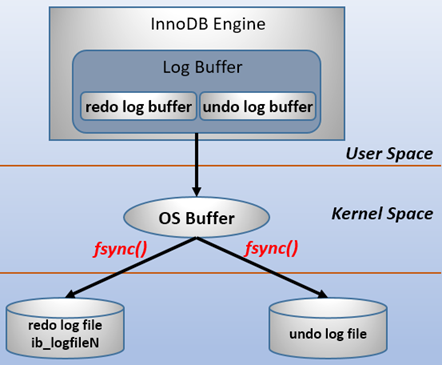
为了确保每次日志都能写入到事务日志文件中,在每次将 log buffer 中的日志写入日志文件的过程中都会调用一次操作系统的 fsync 操作(即 fsync() 系统调用)。
因为 MySQL 是工作在用户空间的,MySQL 的 log buffer 处于用户空间的内存中。要写入到磁盘上的 log file 中 ,中间还要经过操作系统内核空间的 os buffer,调用 fsync() 的作用就是将 OS buffer 中的日志刷到磁盘上的 log file 中。
也就是说,从 redo log buffer 写日志到磁盘的 redo log file 中,过程如下:
MySQL 支持用户自定义在commit 时如何将 log buffer 中的日志刷 log file 中。这种控制通过变量innodb_flush_log_at_trx_commit 的值来决定。该变量有3种值:0、1、2,默认为1。但注意,这个变量只是控制 commit 动作是否刷新 log buffer 到磁盘。
当设置为 0 的时候,事务提交时不会将
log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。也就是说设置为 0 时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。当设置为 1 的时候,事务每次提交都会将
log buffer中的日志写入os buffer并调用fsync()刷到log file on disk中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。- 当设置为 2 的时候,每次提交都仅写入到
os buffer,然后是每秒调用fsync()将os buffer中的日志写入到log file on disk。
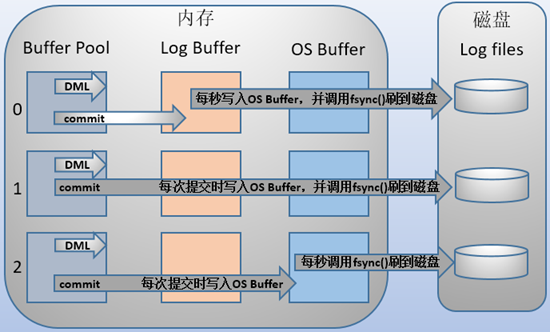
通过上面可以发现,其实值为 2 和 0 的时候,它们的差距并不太大,但 2 却比 0 要安全的多。它们都是每秒从 os buffer 刷到磁盘,它们之间的时间差体现在log buffer 刷到 os buffer上。因为将 log buffer 中的日志刷新到 os buffer 只是内存数据的转移,并没有太大的开销,所以每次提交和每秒刷入差距并不大。
如果 MySQL 程序 发生了崩溃,logbuffer 会发生丢失,但是 os buffer 还是存在。 如果整个服务器发生了宕机,那么 0 和 2 都会丢失 1s 的数据。
Undo log
undo log有两个作用:提供回滚和多个行版本控制(MVCC)。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
undo log 是逻辑日志,可以理解为:
当 delete 一条记录时,undo log 中会记录一条对应的 Insert 记录
当 insert 一条记录时,undo log 中会记录一条对应的 delete 记录
当 update 一条记录时,它记录一条对应相反的 update 记录
一个例子
假设有 2 个数值,分别为 A=1 和 B=2, 然后将 A 修改为 3, B 修改为 4
- start transaction
- 记录 A=1 到 undo log;
- Update A=3
- 记录 A=3 到 redo log
- 记录 B=2 到 undo log
- Update B=4
- 记录 B=4 到 redo log
- 将 redo log 刷新到磁盘
- Commit
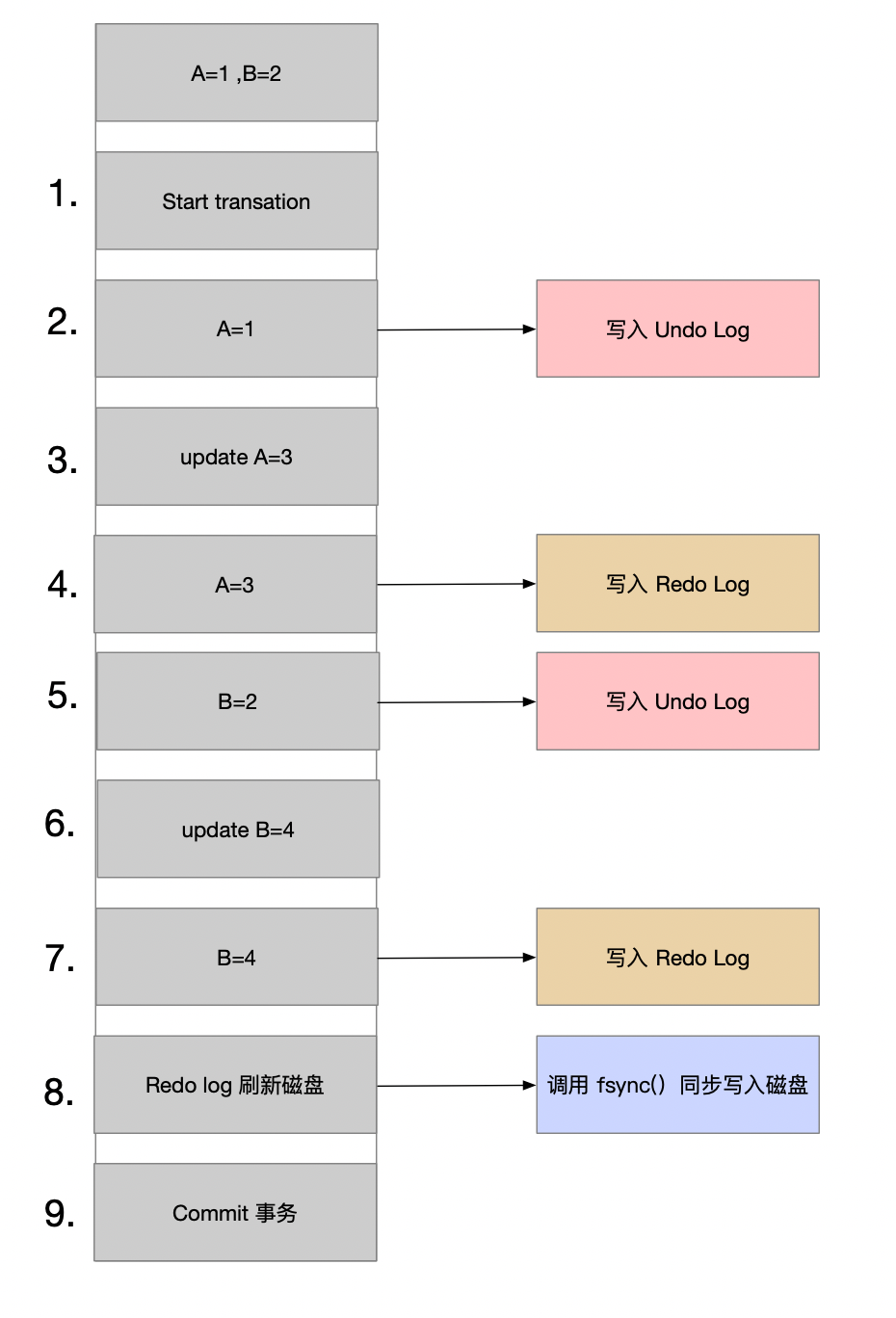
在 1-8 步骤的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。
如果在 8-9 之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时 redo log 已经持久化。
若在 9 之后系统岩机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据 redo log 把数据刷回磁盘
所以,redo log 其实保障的是事务的持久性和一致性,而 undo log,则保障了事务的原子性。
Binlog
Binlog 是 server 层的日志,即使是数据的存储的日志(可以理解成业务日志)。redo log 是 InnoDb 的底层的操作日志。
与 redo 日志的区别
redo 是 Innodb 独有的,binlog 是所有引擎都可以使用的
redo 是物理日志,记录的是在某个数据页上做了什么修改,binlog 是逻辑日志,记录的是这个语句的原始逻辑。
redo 是循环写的,空间会用完,binlog 是可以追加写的,不会覆盖之前的日志信息。
Binlog 中会记录所有的逻辑,并且采用追加写的方式
binLog的格式
binlog 共有三种存储格式: row, statement 和 混合模式。
row: 记录哪行数据被修改的
数据记录方式比较简单,但是可能会产生大量的数据废弃日志(如 更新一个全表)。
statement: 记录修改数据的 SQL ,不记录修改的数据
记录数据的过程,日志量比较小,IO 读写少。缺点是 有些函数并不支持,为了保证能够一致性,必须还需要有一些上下文的信息。
混合模式: 是以上两种模式的混合使用,MySQL 会根据执行的每一条具体的 sql 语句来区分对待记录的日志形式。
一般的语句修改使用 statment 格式保存 binlog ,如一些函数,statement 无法完成主从复制的操作,则采用 row 格式保存 binlog。