探讨 MySQL 事务隔离原理
数据库的事务一共有四个特性:
原子性:代表事务是一个动作,要么同时成功,要么同时失败一致性:事务开始和结束数据完整性没有发生破坏隔离性:两个事务动作相互独立,不受干扰持久性:事务完成后,能够保存到数据库。
那 MySQL 是如何保证这个四个特性的呢?
为了弄明白这几个特性,我们需要先看下事务的隔离级别。
事务隔离级别
事务隔离级别分为 4 种,分别如下:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 读已提交(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
上面的四种隔离级别,是通用的规则,在每一种不同的数据库中有不同的实现。
例如 MySQL 默认的事务隔离级别是 可重复读,但不会产生幻读的问题
为了能够演示事务的隔离的现象,需要做一些准备工作,我的环境是 MySQL 8.0+的版本,如果是其他版本可能命令会有点不同,其他基本一致。
准备工作
创建测试表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
create table tbl_user(
id int primary key auto_increment comment "主键",
user_name varchar(100) comment "用户名",
user_code varchar(100) comment "用户编号",
user_age int comment "用户年龄",
create_time timestamp default now() comment "创建时间",
datachange_lasttime timestamp default now() comment "最后更新时间"
)
alter table tbl_user add index idx_user_name(user_name);
alter table tbl_user add index idx_create_time(create_time);
alter table tbl_user add index idx_datachange_lasttime(datachange_lasttime)
insert into tbl_user (user_name,user_code,user_age) values
('user1','u0001',10),
('user2','u0002',15),
('user3','u0003',20)

查询默认事务级别(8.0)
1
2
3select @@version;/查询版本
show variables like 'transaction_isolation';
关闭自动提交事务
1
2
3show variables like 'autocommit';
set autocommit=0;
show variables like 'autocommit';
准备工作完成后,对于读未提交和串行化读 这两种类型在工作中,使用的并不多,所以此处重点讨论读已提交和可重复读
读已提交
打开两个
mysql客户端,设置默认的事务提交模式为读已提交1
set session transaction isolation level read committed;
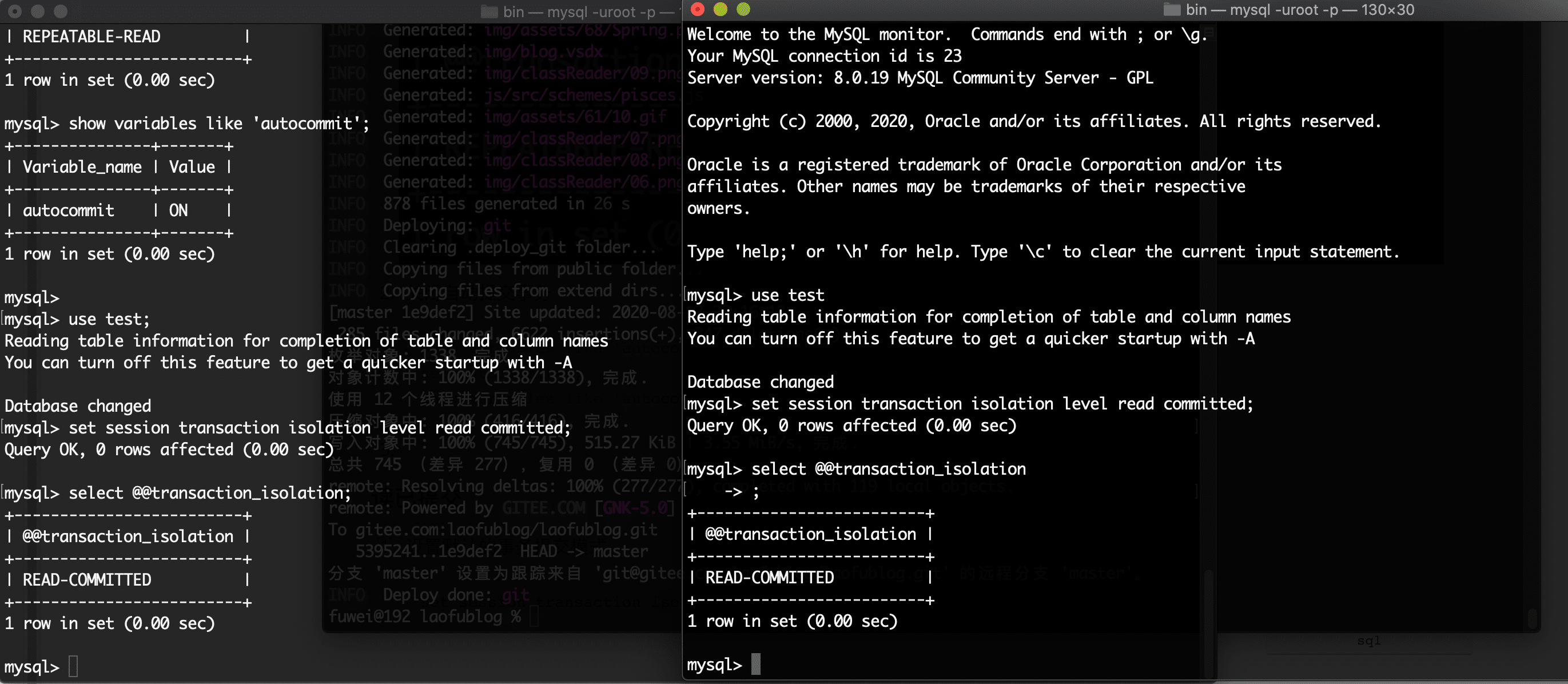
打开两个事务 A , B,在 A 事务中修改数据,不提交事务。
1
2begin;
update tbl_user set user_code='f005' where id=1;分别在 A B 事务中查询数据
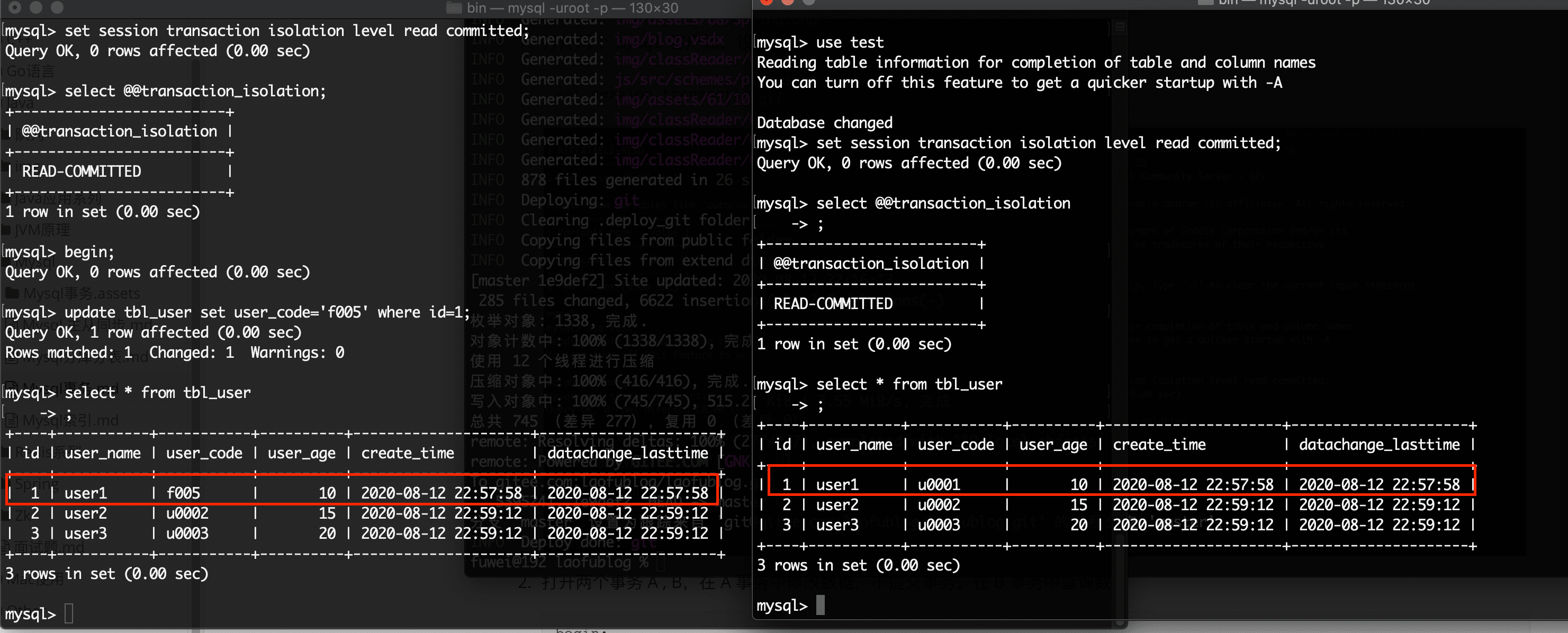
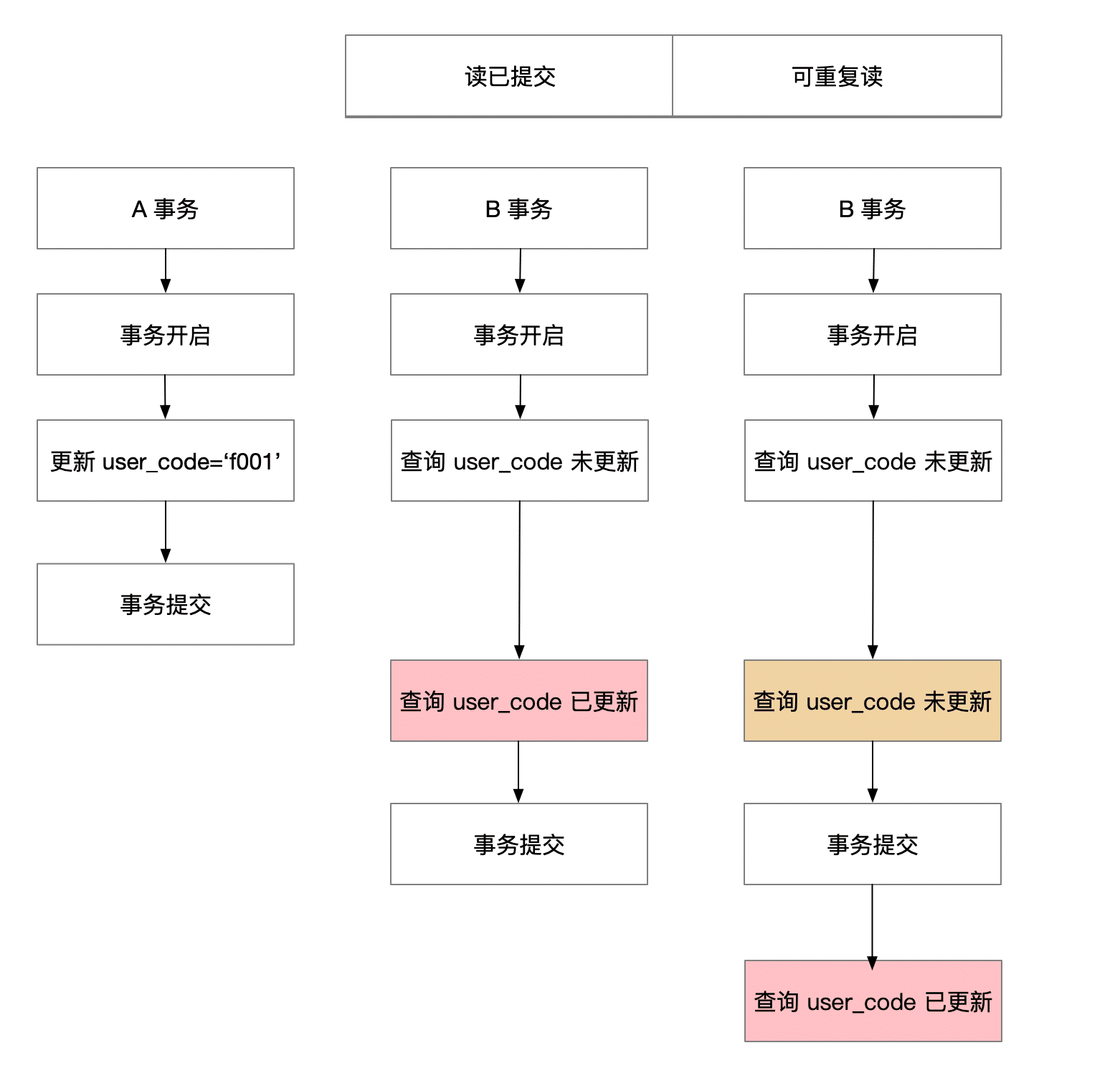
从图上的数据可以看出,由于 A 的数据没有提交,由于事务的隔离级别是
读已提交,所以在 B 事务中是看不到 A 事务中未提交的数据,这样就解决了 脏读 问题
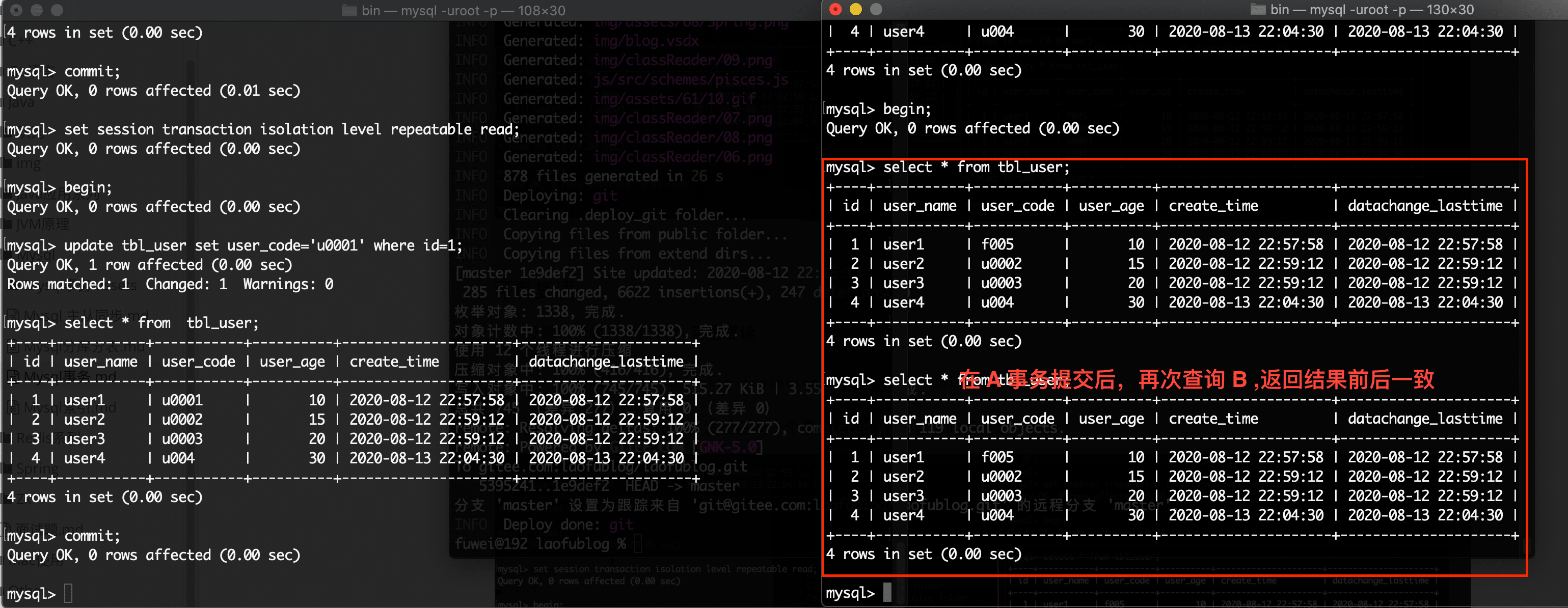
提交 A 事务,在 B 事务中再次查询数据
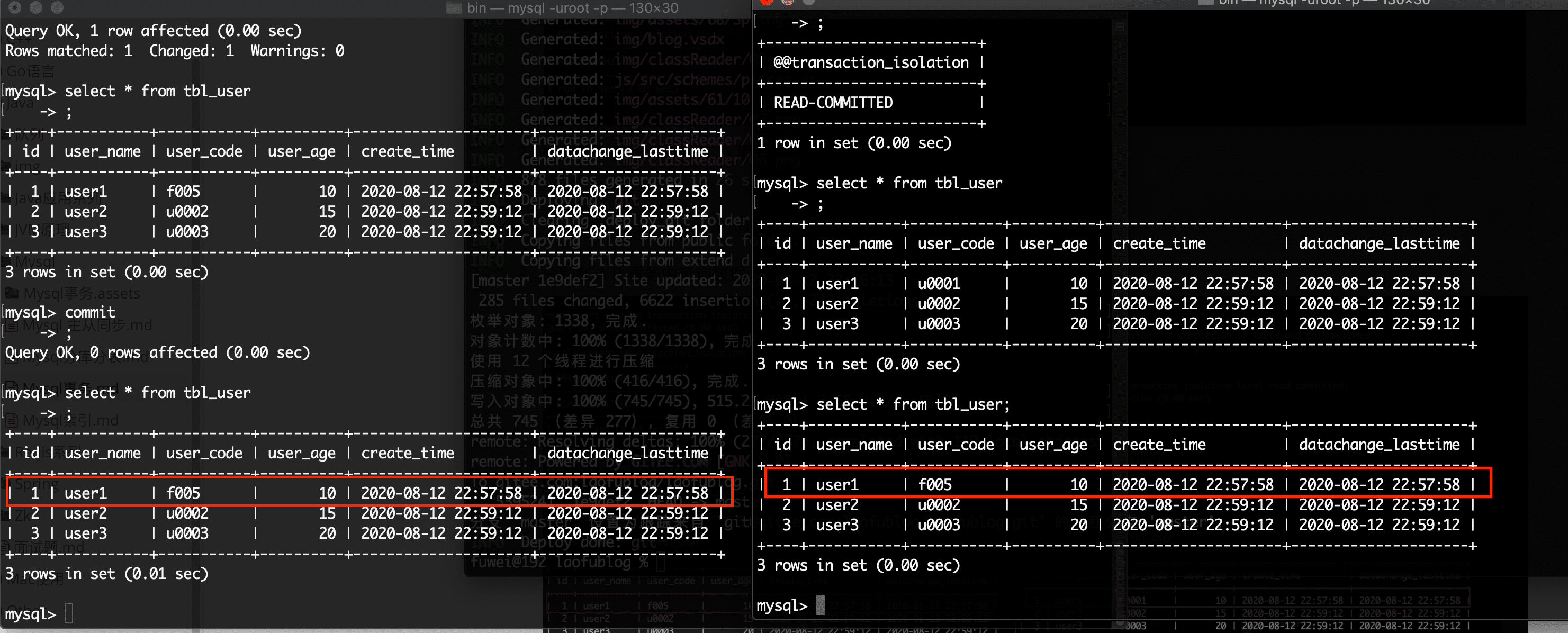
从图上可以看出,B 事务中能够读到最新的数据,这样就带来了一个问题,同一个事务查询相同,但是返回的数据不同,即 不可重复读
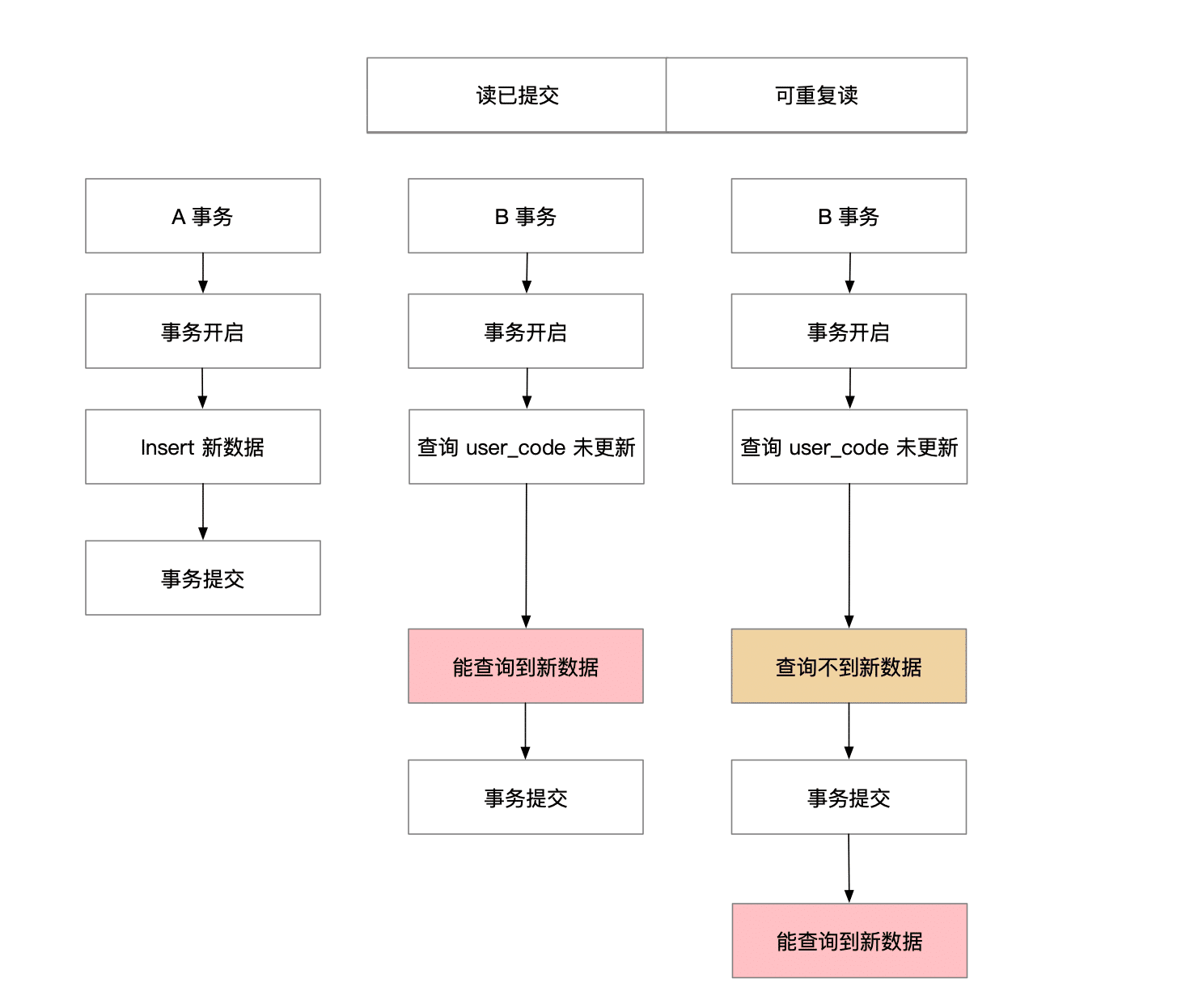
如果在 A 事务中插入一条数据提交事务,在 B 事务中又查询出来一条新数据,这个现象称为幻读
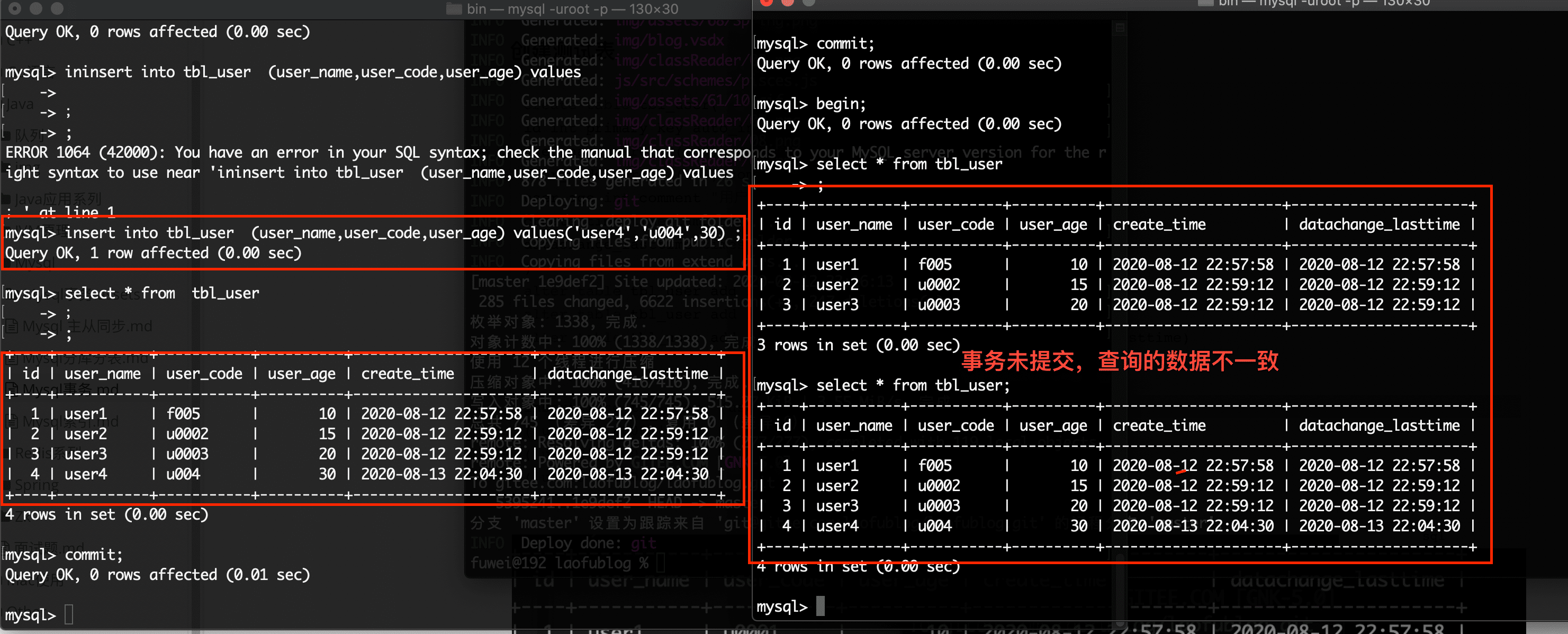
可重复读
设置事务的隔离级别为 可重复读
1
set session transaction isolation level repeatable read;
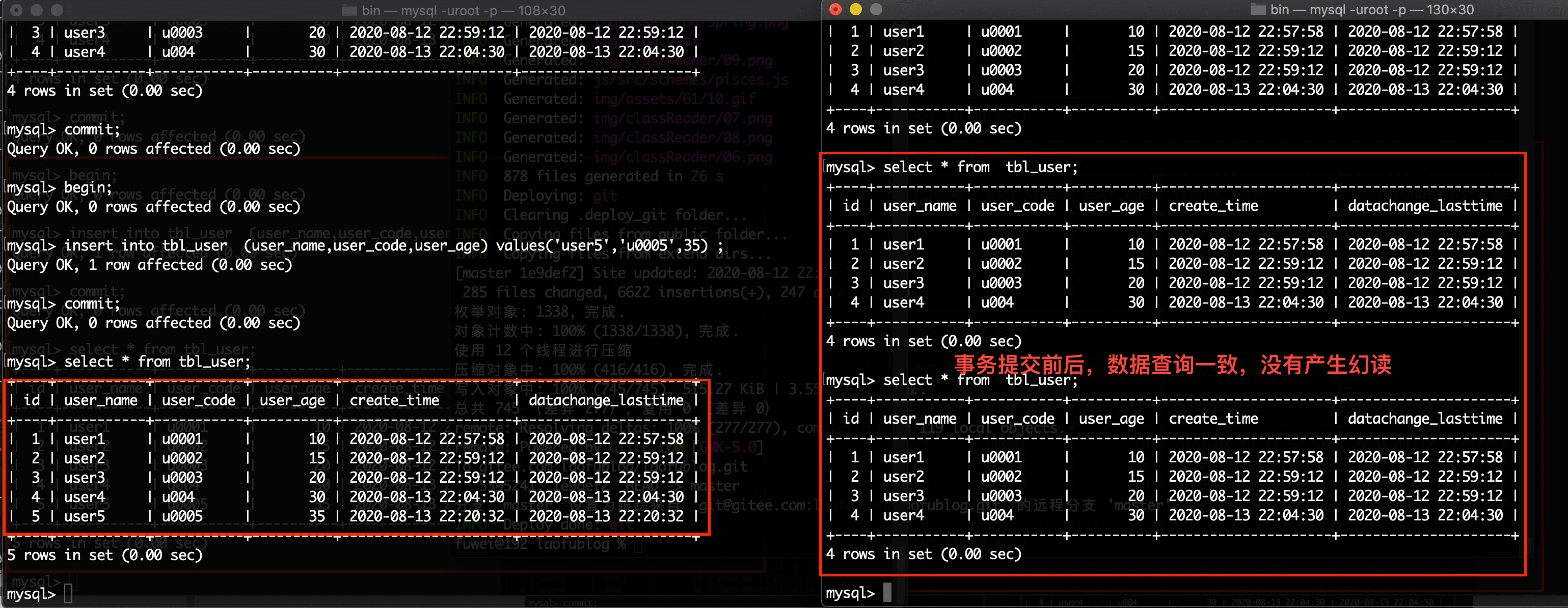
执行上述同样的动作,会发现在同一个事务中,B 事务查询的结果是一致的。
在可重复读的事务隔离级别下,解决了不可重复读的问题, 幻读的问题,也存在。 但是在 Mysql 中,通过特殊的锁,能够避免幻读的产生
总结下上面的额过程,基本如下图:
从上面的过程中,可以思考出来一个问题,查询的一行同样的数据,是如何保证不同的事务查询的数据不同 ?
版本链
如果想要理解版本链,需要先说明下 mysql 的存储的格式。在 MySQL 存储的数据中,会有三个隐藏字段:
| 列名 | 实际名称 | |
|---|---|---|
| row_id | DB_ROW_ID | 行 Id ,唯一标识一条记录,占 6 字节 |
| transation_id | DN_TRX_ID | 事务 ID ,占 6 个字节 |
| roll_pointer | DB_ROLL_PTR | 回滚指针 ,占 7 个字节 |
对于 MySQL 的版本的存储格式 基本如下:
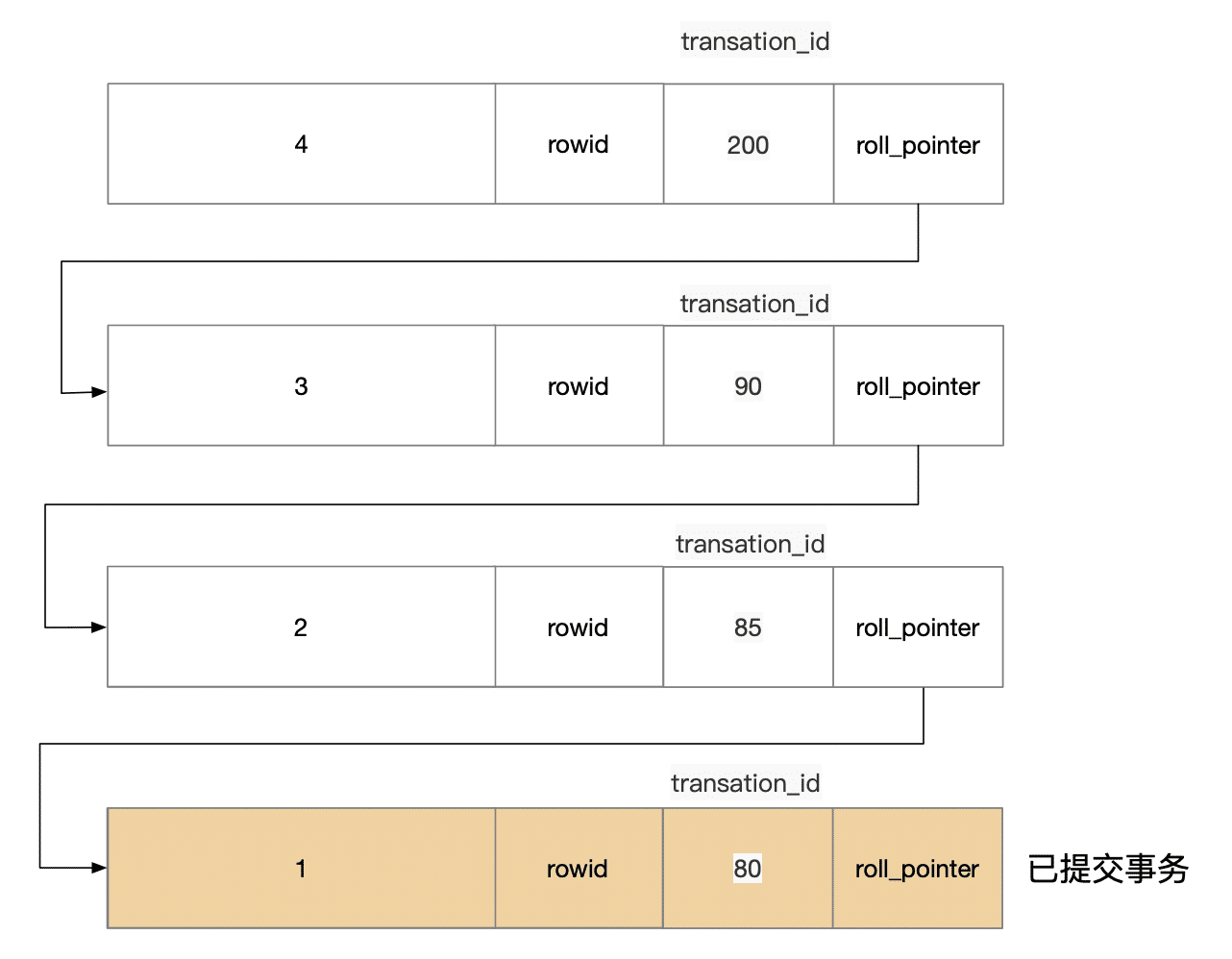
版本链的特性:
- 每修改一个数据,会对数据生成一个版本链
- roll_pointer 会指向前面一个版本
- 每次读取,会读取和事务 ID 符合的数据
对于 A,B 两个事务读取数据的时候,过程如下:
- 假定 A 事务的 ID 是 200 ,B事务的 ID 是 300.
- 当 A 去查询的时候,会查询到
tid=200的数据。 - 当 B 事务去查询的时候,发现没有符合的事务,会怎么办的?
为了搞清楚 B 事务的情况,还需要引入一个概念 ReadView
ReadView
对于事务读取数据时候,会产生生成一个 ReadView. 在 ReadView 中有四个属性:
- m_ids: 代表当前活跃的事务 Id
- min_tx_id: 当前的活跃 id 中的最小值,也就是 m_ids 中的最小值
- max_trx_id : 分配给下一个事务的 id
- creator_trx_id: 表示生成 ReadView的事务的事务 id .
在读已提交的场景下:
B 事务中
m_ids中会存在[300,200,90,85], B 事务在查询的时候,会根据版本链和 m_ids 的属性,来最终确定读取的版本是80.如果这个时候 A 事务完成了,B 中的 m_ids 会更改为
[300,90,85],这个时候 B 事务就能看到 A(200) 事务提交的数据。
在可重复读的场景下:
- 在可重复的场景下,第一个场景和读已提交的场景相同。在 A 事务提交的时候,B 事务中的 m_ids 并不发生修改,所以 B 两次读取的都是 80 对应的数据。
- 这个时候,如果 B 事务提交了,B 事务中的 m_ids 才会发生修改。
综上所说的内容,就是 MVCC (多版本并发控制) 。在READ COMMITTD 和 REPEATABLE READ这两种隔离级别的事务在执行普通的 SELECT 操作访问记录的版本链的过程。可以在不同事务的读写 操作并发执行,从而提升系统性能。
读已提交和可重复读的隔离级别最大的不同,是生成 ReadView 是时机不同。
读已提交在每一次执行普通的 select的操作前都会生成一个 ReadView
可重复读只在第一次进行普通 select前生成一个 ReadView ,后续的查询都是直接复用。
综上分析,我们可以得到一个简单的结论:
MySQL 是通过 MVCC 保证事务的隔离性和一致性的,事务的 commit 和 rollback 保证了一部分原子性。剩余的由锁来保证(下篇博客会写锁的机制)
我们通常都是使用锁的机制来实现并发控制,为什么 Mysql 使用 MVCC ?有什么优势 ?
对于这个问题,我个人的看法如下:
- 锁的本质是锁住一部分内存数据,在高并发的情况下,无论是乐观锁还是悲观锁,性能都很差
- 基于多版本控制,实际是一种空间换时间的思想,对于事务的操作更加的加单,速度更宽
- 使用锁在回滚的时候更为复杂。