消息中间件--03. Kafka文件存储机制
kafka的文件系统
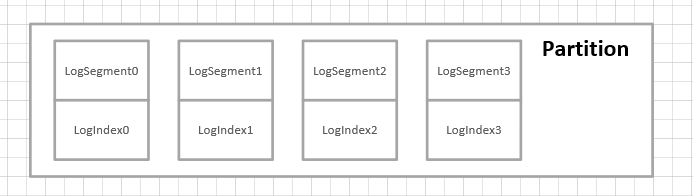
我们知道Kafka是一个Topic下有多个partition,具体结构如下:
下面我们就探究下Kafka的partition的组成到底是什么。
partition的目录
假定我们在指定的一个集群中有两个Broker,有2个topic(testTopic,testTopic1),每个topic的都有2个partition,在不同的partition中互为对方的Leader。

则会产生的文件目录应该为,partition的目录为:
|---testTopic-0
|---testTopic1-0
|---testTopic-1
|---testTopic1-1
从上面的分析中可以看出,kafka在文件的存储中,同一个topic下面有多个不同的partition,每一个partition对应为一个文件夹,partition的命名规则为topic+有序的序号。
partition的文件组成
partition的文件是由Segement组成,使用Segement的好处能够保证单个的文件不会很大,方便删除。文件分为两种类型,分别为log和index,二者组成了一个Segment , Segment的大小可以通过log.segment.bytes这个配置进行修改。
我们可以看下正式环境中的文件信息:
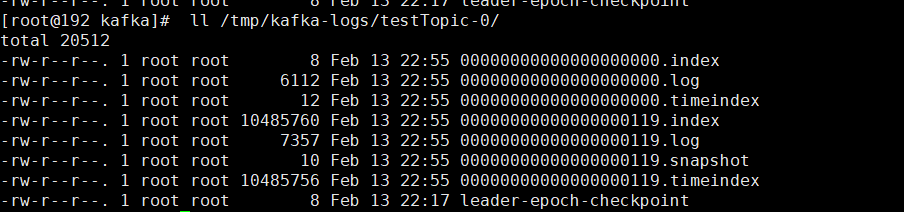
可以看到上面的文件信息为:
1 |
|
上面的文件一共分为5类,index,log,timeidex,snapshot和leader-epoch-checkpoint。
Index:index文件是消息的物理地址的索引文件。
Log:是真正的消息内容。
timeindex:它是映射时间戳和相对offset
snapshot:记录了producer的事务信息
leader-epoch-checkpoint:保存了每一任leader开始写入消息时的offset, 会定时更新.
如何根据索引查询消息
想弄清出这个问题,首先需要了解Index和Log的对应关系。
首先他们的文件最后的数字是当前文件消息的最开始的地址,例如我需要找地址offset=124的消息,那需要加载00000000000000000119.index 这个索引文件, 由于消息文件不是很多, 所以寻找的速度非常快。
Index文件结构:
Index每一个索引项为8字节,其中相对offset占用4字节,消息的物理地址(position)占用4个字节

Log的文件结构:
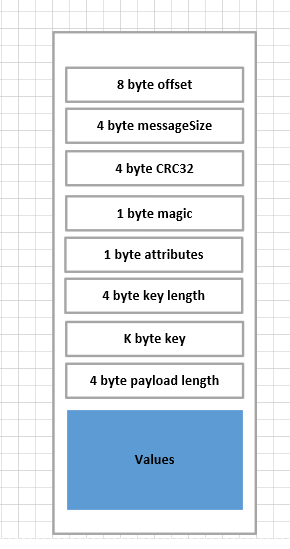
log文件的参数说明
Index和Log的映射示意图:
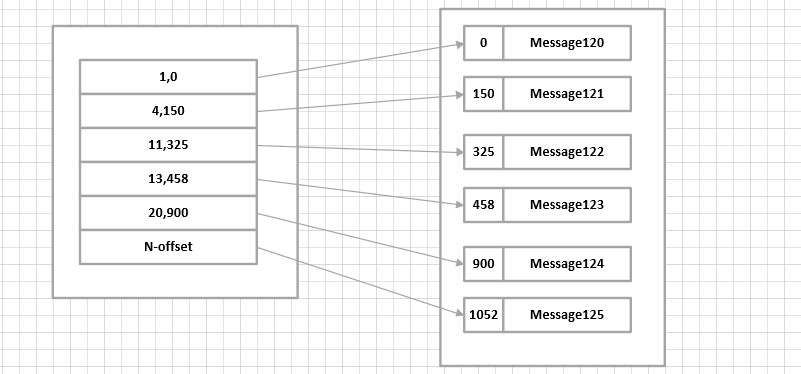
当我们想找第130的消息的时候,我们首先减去当前Index的最开始的地址(119),所以我们得到130-119=11的Index索引,然后顺序查找Index的地址,找到11,325这个节点后 ,325就是消息真实的偏移地址。