一文彻底了解Mysql索引
在不借助DB引擎情况下,想完成数据的持久化存储,最简单的方法写一个文件存在本地,读取的时候加载文件到内存,然后进行筛选。 存储一个user在本地。
1 | id|userName|userCode|sex|phoneNumber |
上面满足了我们的需求,看到这种数据格式,查询的时间复杂度为O(n).
而且在每次读取文件的时候,需要把所有的数据都加载到内存(全表扫描),对系统的IO读写也很高。
解决上面的问题的最先想到的办法,再增加加一个文件(索引文件),根据字段(id)构建一个Hash表映射,哈希表中存储的是哈希值和数据对应的地址。 由于没有具体的数据,所以这个文件小的多,加载的成本比源文件低。
每次查询先hash对应得字段的值,然后直接在Hask表中找到地址,加载数据返回查询结果,时间复杂度为O(1)这个就是哈希索引雏形。
hash的加入解决查询的问题,但是局限性也很多,如果精确查询id=1能够发挥hash表的优势,查询中如果有>,<,<>等查询的时候,就无法使用Hash索引。
能够提高搜索效率的数据结构除了hash表外,还有树形结构,二叉搜索树,B树等。
采用二叉树时候,为了避免查询的深度太深,采用平衡二叉树。 假设user表有10条数据,然后把id作为索引构建成一个二叉平衡树,创建好的数据结构作为索引存储到文件中。
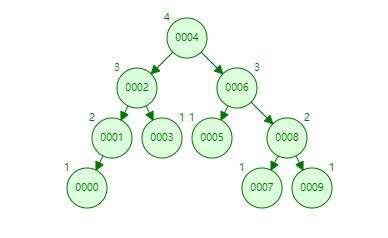
二叉树的深度和节点数的关系为N=2^n-1,当节点个数为10的时候,树的深度就已近达到了4,这对于搜索来说效率非常的低 。
由于二叉树的特点,根节点只能存储一个数据,而系统每次的IO交换数据最小为4KB,所以二叉树对于系统IO的读取效率也不高。
总结一下,不用二叉树的原因:1. 深度太深,不利于搜索 2. 节点太小,不利于系统IO。
B树的引入正是为了解决二叉树的问题,B树的结构如下:

B树有以下几个有点:
- 一个节点多个数据,有利于控制系统IO读写
节点数据多,能够减少树的高度
对于mysql,索引使用的是B+树的数据结构,B+树具有高度低,关键字存储多,更友好操作系统的IO的读写。
mysql有Mysam和InnerDB两个存储引擎,Mysam是数据和索引分开,InnerDb数据和索引是在一个文件。
Mysam
mysam存储存引擎会创建三个文件.frm,.MYD,.MYI,MYD是存储的数据和MYI是索引文件。
Mysam引擎维护一个主键索引,主索引和自建索引地位相同,都直接每个节点都连接到数据文件, 由于辅助索引直接连接到文件,查询效率比较高,如果一旦数据的改动,会导致所有索引变动, O的操作比较多,效率低。 (mysql 5.5 以前默认DB引擎)

InnerDB
InnerDB引擎会创建两个文件.frm,.ibd,其中ibd是索引和数据的混合文件。
InnerDB中的辅助索引叶子节点只连接到主键索引对应的值,每次查询的时候,首先查询出自建索引节点,根据节点对应的主键索引的值,再查询主键索引。所以InnerDB的查询效率多一次主键索引的查询。
正是由于自建索引与数据没有直接的联系,所以数据的改动,只需要对主键的索引进行修改,不用额外的维护自建索引,所以修改数据InnerDb比较高。

覆盖索引
覆盖索引是不用扫描表,能通过查询索引直接返回想要数据,这个索引就称为覆盖索引。 例如:
user表采用InnerDb作为引擎,使用userName所谓索引,id为主键,那么下面的几个查询都是覆盖索引查询
1 | select userName from user where userName=? |
所以为什么select * 在查询的时候很忌讳的原因,因为永远走不到覆盖索引(除非全部都是索引列)
联合索引
当一个表有超过一个字段作为索引,这个索引称为联合索引,例如:
user表,使用userName,phoneNo作为联合索引,则对应索引结构为:

其中ABCDEF代表userName,后面的数字代表手机号(中间是否有连接符,此处不考虑)
在联合索引中, 使用userName单个字段进行检索的时候,由于是字符串的匹配规则,所以也会使用到索引。
如果创建了一个(ABC)三个字段的联合索引,就等于同时创建了 A,AB,ABC三个联合索引,这个就是索引的左匹配原则。
数据离散型决定索引的好坏
在建立索引的时候,有一个离散型的指标,如果查询的某一列的离散型过低,即使有索引mysql也不会查询索引(因为加载索引也消耗时间) 。
离散型的计算公式为:count(disticnt)/count(0).
为什么离散型越高,查询效率越好呢?

如上图,如果查找数据为1的节点,几乎需要在50%的数据中寻找。所以重复数据越高,性能越低。
索引使用的误区
索引是不是越多越好?
答: 肯定不是,对于查询来说可能是,但对于修改绝对是灾难。
为什么like ‘abc%’走索引,而
like %abc%和like %abc不走索引答:左匹配和数据离散决定的,
abc%在已知开头的情况下能够定位到大概的节点顺序,%abc%和%abc无法定位,只能全部扫描。如果数据都以abc开头的数据,也无法走到索引
如果字段使用函数,一定不能走索引吗?
答:因为函数的不确定性,所以函数一般不会走索引。如果能把函数的值提前计算出来,是不是就可以走索引查询?这个就是5.7版本以上支持的
函数索引
索引下推是什么意思?
答:索引下推是指在一个索引下,推测另一个索引的数据。
user表有一个联合索引(username,age),如果我们的sql:1
2select * from user where userName like 'abc%' and age>10
sql的查询过程有两种方式:
先根据联合索引最左匹配原则,使用
userName回表查询的所有的数据,然后在找出大于10的数据根据(username,age)联合索引查询所有满足名称以”abc”开头的索引,然后直接再筛选出年龄小于等于10的索引,第二种方式是索引下推
聚集索引是什么?
答:聚集索引又称为二级索引,可以理解成数据的原始顺序,这个索引的结构是B树。其他的非聚集索引的叶子节点的值,都存储的是这个索引的对应节点的值。