B-Tree和B+树
B树和B+树是很多数据库索引采用的数据结构,为什么会使用B树,而不采用更常见的二叉树的呢?
举个例子,有这么几个数字:1,2,3,4,5,6,7,8,9,0,分别生成AVL树,B树
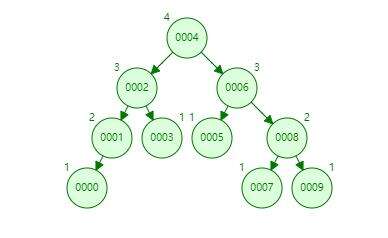
二叉树生出的树的度为4,而3阶B树高度只是3.如果B树的阶数再多的话,就可以获得更小的高度度。
(6阶的B树)
树的度带来更深入查询,会带来更多的IO读写。
除了二叉树的深度太深的原因,二叉树对于操作系统IO的读取也不是特别的友好。二叉树的节点过于简单,信息过于少。当操作系统进行IO操作的时候,最少读取的字节数是4K,为了保证IO的读取性能,也可能进行预读下个节点等等。
如果二叉树的一个节点只有1KB的话,操作系统每次读取二叉树的时候,只有1KB的有效信息,那这次IO操作的剩余的3KB就是无效的读取。
B树
B树又称为多路平衡查找树,在上面看到了B树的简单结构,在真正的文件存储结构如下:
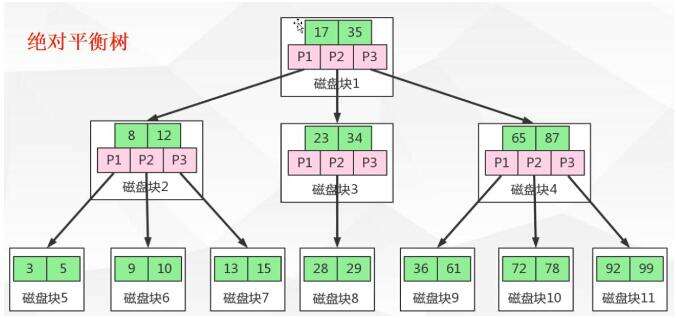
B树的结构可以保证树的高度不会太高,节点都是一个单元的磁盘块的信息,可以充分的利用操作系统中的IO的读写和预读的能力。
在Sqlserver中索引的存储使用的是B树 ,而在mysql中使用的是B+Tree.
B+树
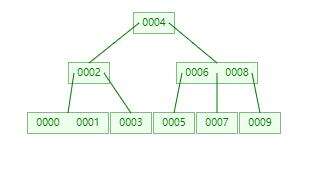
B+树是B树的加强形势,用B+树表示0-9十个数字结构如下:
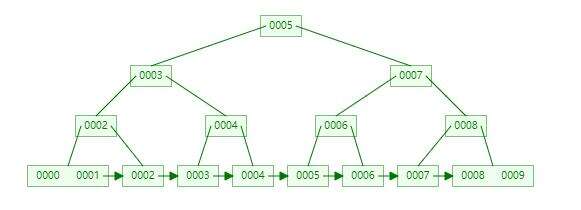
B+树有以下特点:
- 与B树不同,数据都只会存在叶子节点,非叶子节点不保存数据,只负责查找。
- B+树叶子节点是有顺序的,之间有相互的连接
比如在上面的图片中,我想找到5对应的数据,具体的查询过程结果如下:
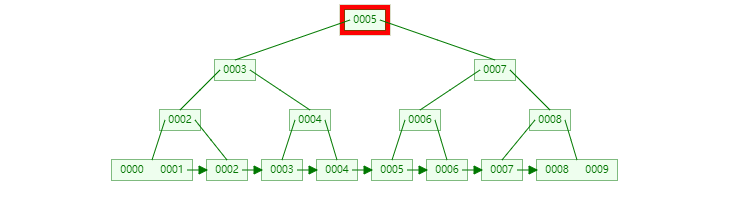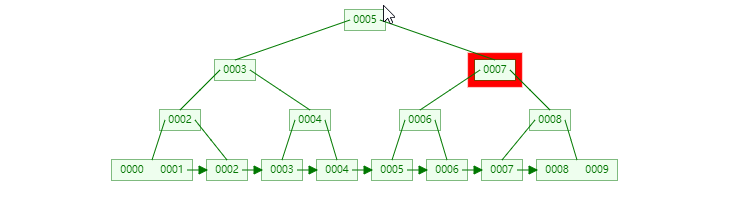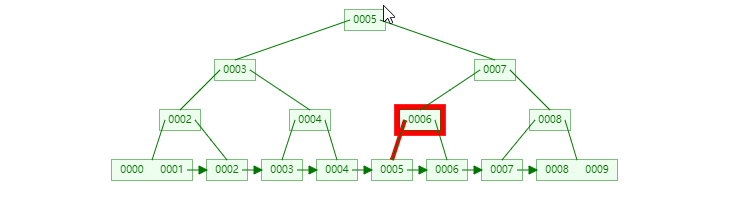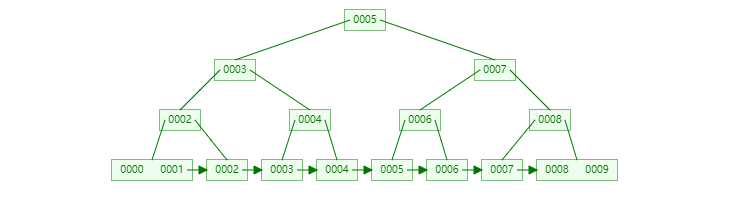
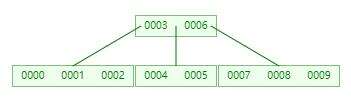
具体在磁盘上面的结构如下:
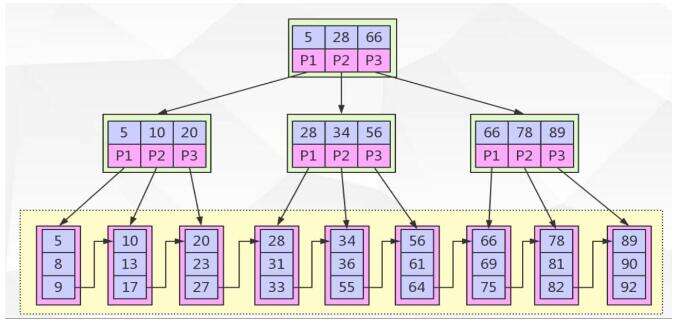 {:height=”100px” weight=”100px”}
{:height=”100px” weight=”100px”}
B+树的优点
- 节点可以存储比B树更多的关键字数据,查询更具有效率
- B+树叶子存储数据,可以做到局部顺序的IO读写
- B+的叶子节点有顺序,所以排序的能力更强
- 查询复杂度和IO读写更加稳定(相对B树)