Java中lambda表达式详解
为什么使用lambda
在Java中我们很容易将一个变量赋值,比如int a =0;int b=a;
但是我们如何将一段代码和一个函数赋值给一个变量?这个变量应该是什么的类型?
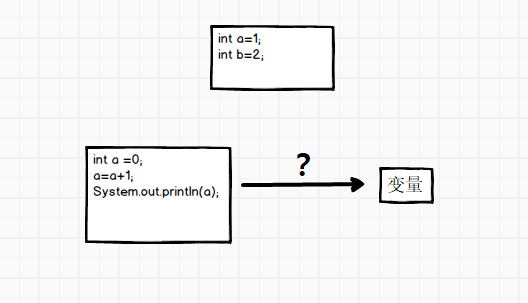
在Javascript中,可以用一个对象来存储。
1 | var t=function() |
在Java中,直到Java8的lambda的特性问世,才有办法解决这个问题
————————————————————————-
什么是lambda
什么是lambda? lambda在程序中到底是怎样的一个存在? 首先看代码:
1 |
|
上面的代码中,e是一个lambda的对象,根据Java的继承的特性,我们可以说e对象的类型是继承自eat接口。而e1是一个正常的匿名类的对象.
通过对比, 可以说 lambda的表达式其实是接口的实现的“另一种方式”。这种方式更加简洁,更容易阅读。除了代码层面的简洁外,在编译的结果时候lambda也不会产生一个多余的匿名类。
对于eat这个特殊的接口,称之为:函数式接口
————————————————————————-
lamda的优点
- 代码缩减
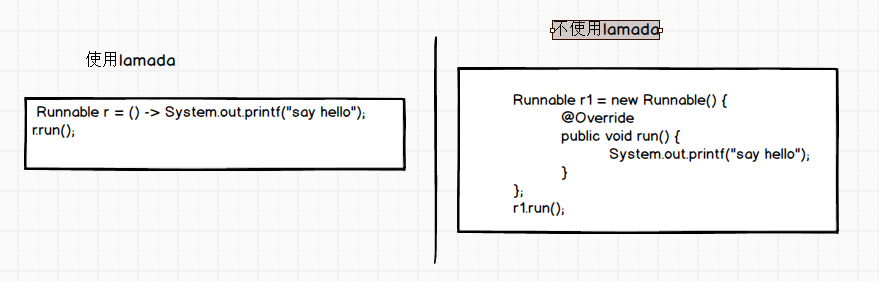
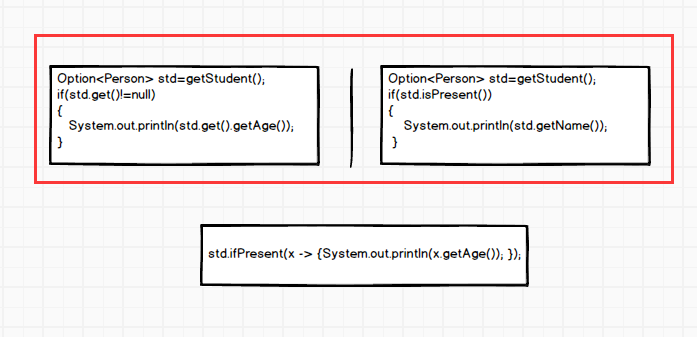
Option的使用简化代码
假如我们有个方法,能够产生一个Option
对象std 1
2
3
Option<Person> std=getStudent();
是否为空的判断
返回不为空的对象
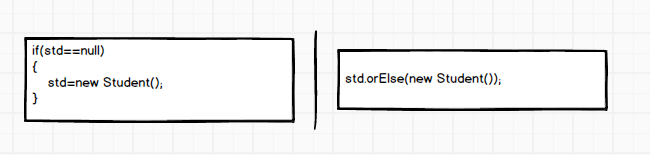
多重if else的简化
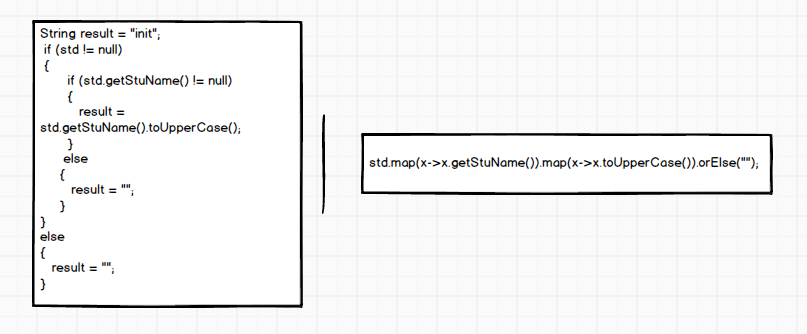
————————————————————————-
函数式接口
什么是函数式接口?这个是我们理解Lambda表达式的重点,也是产生lambda表达式的“母体”,这里我们引用一个比较容易理解的说法:
函数式接口是 一个只有一个抽象方法(不包含object中的方法)的接口。
这个需要说明一点,就是在Java中任何一个对象都来自Object 所有接口中自然会继承自Object中的方法,但在判断是否是函数式接口的时候要排除Object中的方法,下面举几个例子如下:
1 | //这个是函数式接口 |
对于是否是函数式接口,Java8中也提供了一个专用的注解:@FunctionalInterface。通过这个注解,可以确定是否是函数式接口:
1 |
|
下面我们写一段lambda简单的代码,找出指定的身份证号码,并打印出来。

最终的调用:

对于上面的代码实现,在我们调用excutor方法前,并不知道findName的实现方法,直到在最后把一个方法作为参数传入到excutor方法中。
反思:函数式接口NameCheckInterface,是不是可以用来表示所有返回值为bool类型的,有两个形参(类型是passager 和String类型)的lambda表达式?
如果我们再配合泛型的话,是不是我们只需要定义一个通用的函数式接口?下面我们改写下代码:
1 |
|
对应的调用方法
1 |
|
对于这段代码,可以得出lambda中的函数式接口是可以公用的,而jdk中也已经定义了很多通用的函数式接口。
————————————————————————-
常用的函数式接口
在jdk中通用的函数式接口如下(都在Java.util.function包中):
1 |
|
PS:上面是基本的方法,其他的都是基于这几个扩展而来
如果上面的代码使用jdk中的函数式接口的话,就不用额外的定义NameCheckInterface和PrintInterface 接口了。根据上面的参数和返回值的形式,可以使用BiFunction和Consumer直接改写excutor方法:
1 |
|
————————————————————————-
函数的引用
从上面的demo中,使用通用的函数表达式能够减少自定义函数式接口,为了进一步简化代码,lambda表达式可以改写成函数的引用的形式
函数的引用是lambda表达式的更简洁的一种写法,也是更能体现出函数式编程的一种形式,让我们更能理解lambda终归也是一个“函数的对象”。 下面我们改写一个例子:
1 |
|
在上面的demo中lambda表达式被我们改写成System.out::printf这个形式,等于我们把一个函数直接赋值给了一个c2对象,这里我们可以俗称(非官方)c2为Java函数的一个对象,这个也结局填补了Java中一个空白。
————————————————————————-
函数引用的规则
对于Java中lambda改成函数的引用要遵循一定的规则,具体可以分为下面的四种形式:
静态方法的引用
如果函数式接口的实现恰好可以通过调用一个静态方法来实现,那么就可以使用静态方法引用
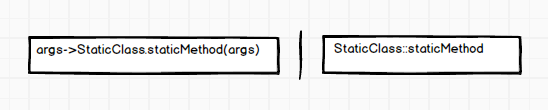
1
2
3
4
5
6
Consumer<String> c1 = r -> Integer.parseInt(r);
c1.accept("1");
Consumer<String> c2 =Integer::parseInt;
c1.accept("2");
实例方法引用
如果函数式接口的实现恰好可以通过调用一个实例方法来实现,那么就可以使用实例方法引用

1
2
3
4
5
6
Consumer<String> ins1 = r -> System.out.print(r);
c1.accept("1");
Consumer<String> ins2 =System.out::print;
c1.accept("2");
对象方法引用
抽象方法的第一个参数类型刚好是实例方法的类型,抽象方法剩余的参数恰好可以当做实例方法的参数。如果函数式接口的实现能由上面说的实例方法调用来实现的话,那么就可以使用对象方法的引用。

1
2
3
4
5
Function<BigDecimal,Double> fuc1=t->t.doubleValue();
fuc1.apply(new BigDecimal("1.025"));
Function<BigDecimal,Double> fuc2=BigDecimal::doubleValue;
fuc2.apply(new BigDecimal("1.025"));1
2
3
4BiFunction<BigDecimal, BigDecimal, BigDecimal> func3 = (x, y) -> x.add(y);
func3.apply(new BigDecimal("1.025"), new BigDecimal("1.254"));
BiFunction<BigDecimal, BigDecimal, BigDecimal> func4 = BigDecimal::add;
func4.apply(new BigDecimal("1.025"), new BigDecimal("1.254"));构造方法引用
如果函数式接口的实现恰好可以通过调用一个类的构造方法来实现,那么就可以使用构造方法引用。
 ]
]1
2
3
4Consumer<String> n1 = r ->new BigDecimal(r);
c1.accept("1");
Consumer<String> n2 =BigDecimal::new;
c1.accept("2");
stream API的引用
Stream是处理数组和集合的API,Stream具有以下特点:
- 不是数据结构,没有内部存储
- 不支持索引访问
- 延迟计算
- 支持过滤,查找,转换,汇总等操作
对于StreamAPI的学习,首先需要弄清楚lambda的两个操作类型:中间操作和终止操作。 下面通过一个demo来认识下这个过程。
1 | Stream st=Arrays.asList(1,2,3,4,5).stream().filter(x->{ |
当我们执行这段代码的时候,发现并没有任何输出,这是因为lambda表达式需要一个终止操作来完成最后的动作。 我们修改代码:
1 | Stream st=Arrays.asList(1,2,3,4,5).stream().filter(x->{ |
对应的输出结果是:
1 |
|
为什么会有这个输出呢?因为在filter函数的时候并没有真正的执行,在forEach的时候才开始执行整个lambda表达式,所以当执行到4的时候,filter输出之后,forEach也执行了,最终结果是1234455
对于Java中的lambda表达式的操作,可以归类和整理如下:
中间操作:
- 过滤 filter
- 去重 distinct
- 排序 sorted
- 截取 limit、skip
- 转换 map/flatMap
- 其他 peek
终止操作
- 循环 forEach
- 计算 min、max、count、 average
- 匹配 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny
- 汇聚 reduce
- 收集器 toArray collect
————————————————————————-
常用的几个lambda
下面我们对这几个常用的lambda表达式写几个demo,首先定义公共的Student类:
1 | public class Student { |
forEach
forEach:代表循环当前的list ,下面的例子是循环打印出student的名字
1 |
|
filter
根据条件过滤当前的数据,获得分数大于80的学生名称
1 |
|
distinct、sorted 、group
去除重复数据
1
2
3
studentList.stream().distinct().forEach(x -> System.out.println(x.getStuName()));
单条件排序和多条件排序
1
2
3
4
5
6
studentList.stream().sorted(Comparator.comparing(Student::getScore)).forEach(x -> System.out.println(x.getStuName()));
//多条件排序
studentList.stream().sorted(Comparator.comparing(Student::getScore).thenComparing(Student::getStuName)).forEach(x -> System.out.println(x.getStuName()));
group 的使用
1
2
3
System.out.println(studentList.stream().collect(Collectors.groupingBy(x->x.getAge(),Collectors.counting())));
limit、skip
跳过多少,取多少个元素,可以根据当前的数据进行分页
1 |
|
map/flatMap
map是一个转换的工具,提供很多转换的方法,mapToInt,mapToDouble
1 |
|
上面的结果是输出当前的所有同学的得分。
flatMap是一个可以把子数组的值放到数组里面, 下面的实例是把所有的名字都拆开成一个新的数组
1 |
|

min、max、count、 average
一组常用的统计函数:
1 |
|
anyMatch、noneMatch、 allMatch、 findFirst、 findAny
anyMatch: 操作用于判断Stream中的是否有满足指定条件的元素。如果最少有一个满足条件返回true,否则返回false。
noneMatch: 与anyMatch相反。allMatch是判断所有元素是不是都满足表达式。
findFirst: 操作用于获取含有Stream中的第一个元素的Optional,如果Stream为空,则返回一个空的Optional。若Stream并未排序,可能返回含有Stream中任意元素的Optional。
findAny: 操作用于获取含有Stream中的某个元素的Optional,如果Stream为空,则返回一个空的Optional。由于此操作的行动是不确定的,其会自由的选择Stream中的任何元素。在并行操作中,在同一个Stram中多次调用,可能会不同的结果。在串行调用时,都是获取的第一个元素, 默认的是获取第一个元素,并行是随机的返回。
1 |
|
reduce
对于reduce的使用,应该在js中也有接触到,但也是比较小众的功能,但使用起来功能却非常的强大,先看一个正常的demo:
1 |
|
打印结果:
1 | x : 1 |
可以看出:
- reduce是一个循环,有两个参数
- 第一次执行的时候x是第一个值,y是第二个值。
- 在第二次执行的时候,x是上次返回的值,y是第三个值
….
直到循环结束为止。
再修改代码如下:
1 |
|
1 | x : 100 |
toArray、collect
toArray和collect是两个收集器,toArray是把数据转换成数组,collect是转成其他的类型。这里就不在讨论了。1
2
3
System.out.println(studentList.stream().collect(Collectors.groupingBy(x->x.getAge(),Collectors.counting())));